
Компания Comino недавно предоставила нам для обзора последнюю версию Comino Grando, сконфигурированную с восемью видеокартами NVIDIA RTX PRO 6000 Blackwell, каждая с 96 ГБ видеопамяти, что в сумме составляет 768 ГБ графической памяти. Мы уже тестировали Comino в 2024 году, в конфигурации с 6 видеокартами RTX 4090 , предлагающей в общей сложности 144 ГБ графической памяти, а также версию с NVIDIA H100 . Это последнее обновление знаменует собой существенный скачок в развитии как по объему памяти, так и по диапазону рабочих нагрузок, которые может обрабатывать платформа.

Grando — это специально разработанная 4U-платформа, призванная решить критическую проблему баланса между высокой плотностью вычислительных ресурсов графического процессора и эффективным управлением температурным режимом. В то время как стандартные корпуса с воздушным охлаждением не выдерживают постоянной нагрузки в 600 Вт и более, характерной для современных профессиональных видеокарт, Grando использует принципиально иной подход, построенный с нуля на основе архитектуры жидкостного охлаждения, способной рассеивать колоссальные 6,5 кВт непрерывного тепла. Это не модернизация и не второстепенное решение; весь корпус, от инвертированной компоновки материнской платы до системы быстроразъемных соединений с цветовой кодировкой, разработан с учетом контура охлаждения.
В результате получилась платформа, способная вместить восемь профессиональных графических процессоров с полной тепловой мощностью (TDP) в одном корпусе форм-фактора 4U, работающих круглосуточно в условиях окружающей среды от 3 до 38 °C, без теплового троттлинга, без шумового воздействия высокоскоростного воздушного охлаждения и без ущерба для ремонтопригодности. Для организаций, развертывающих задачи вывода ИИ, обучения машинного обучения или высокопроизводительные задачи моделирования в масштабе предприятия, Grando предлагает нечто действительно редкое: сервер, который не заставляет вас выбирать между плотностью размещения, теплоотводом и надежностью.
Технические характеристики Comino Grando
В таблице ниже приведены физические характеристики и поддерживаемые аппаратные конфигурации платформы Comino Grando.
| Технические характеристики / Особенности | Комино Грандо |
|---|---|
| Сервер и стойка Comino Grando | |
| Холодопроизводительность | 6,5 кВт (максимум 6500 Вт при температуре входящего воздуха 20°C) |
| Материнские платы | До EATX и EBB |
| Графические процессоры (сервер) | До 8; NVIDIA: RTX A6000, RTX 6000 ADA, RTX PRO 6000, A40, L40, L40S, A100, H100, H200 |
| Графические процессоры (рабочая станция в стоечном исполнении) | До 6; NVIDIA: 3090, 4090, 5080, 5090, RTX A6000, RTX 6000 ADA, RTX PRO 6000, A40, L40, L40S, A100, H100, H200; AMD: W7800, W7900 |
| ЦП | До 2 процессоров; Односокетные: Intel Xeon W-2400/2500 и 3400/3500, Intel Xeon Scalable 4-го и 5-го поколений, XEON 6, AMD Threadripper PRO 5000WX, 7000WX, 9000WX, AMD EPYC 9004/9005 Двухсокетные: Intel Xeon Scalable 4-го и 5-го поколений, XEON 6, AMD EPYC 9004/9005 |
| БАРАН | До 2 ТБ |
| Накопители M2 | До 8x NVME |
| Хранилище | Корзины для SSD с возможностью горячей замены на задней панели: до 4 SSD с возможностью горячей замены (4 x 7 мм или 2 x 15 мм) и до 4 дополнительных (4 x 7 мм или 2 x 15 мм) вместо 4-го блока питания; Внутренняя корзина для 3,5-дюймовых SSD: до 4 x 3,5″ или 4 x 2,5″ 15 мм или 12 x 2,5″ 7 мм; Внутренние слоты для 2,5-дюймовых SSD: до 4 x 2,5″ SSD 7 мм |
| Источник питания и рабочее напряжение | До 4 блоков питания мощностью 2000 Вт с возможностью горячей замены при напряжении 180-264 В; до 4 блоков питания мощностью 1000 Вт с возможностью горячей замены при напряжении 90-140 В. Режимы резервирования: 4+0, 3+1, 2+2. |
| Уровень шума | 39–70 дБ |
| Лан | До 2x 10 Гбит/с на материнской плате и до 400 Гбит/с в PCIe. |
| ОС | Ubuntu / Windows 11 (Pro/Home) / Windows Server |
| Технические характеристики и система охлаждения | |
| Жидкостное охлаждение | Процессор с VRM и видеокарта с GDDR и VRM |
| Водохранилище | Бутылка Comino Custom объемом 450 мл со встроенным дозатором. |
| Фанаты | 3x Сверхвысокопроизводительные 6200 об/мин (высокий уровень шума) или 3x Высокопроизводительные 3000 об/мин (низкий уровень шума) |
| Установка | Устанавливается в 19-дюймовую стойку или может использоваться как автономная рабочая станция. |
| Необходимое место в стойке | 4U |
| Размер | 439 x 681 x 177 мм (без ручек и выступающих частей) |
| Масса | 4 видеокарты: 49 кг (нетто), 67 кг (брутто) 6 видеокарт: 52 кг (нетто), 70 кг (брутто) 8 видеокарт: 55 кг (нетто), 72 кг (брутто) |
| Диапазон рабочих и температур хранения | Температура хранения: -5–50°C / 23–122°F. Рабочая температура: 3–38°C / 38–100°F. |
| Система мониторинга Комино (CMS) | |
| Обзор | Контроллерная плата с датчиками и программным обеспечением для мониторинга в реальном времени. |
| Основные преимущества | Мониторинг системы охлаждения и процессора/видеокарты, веб-интерфейс, журнал системы охлаждения, централизованный мониторинг для рабочих групп. |
| Датчики и подключенные устройства | Температура (воздуха и охлаждающей жидкости), влажность в %, напряжение, расход охлаждающей жидкости, уровень охлаждающей жидкости в расширительном бачке, вентиляторы, насосы, материнская плата, дисплей и кнопки. |
| Возможности интеграции | Настройте мониторинг через REST API и передавайте данные с датчиков в программное обеспечение для мониторинга (например, Zabbix, Grafana) или базы данных (например, InfluxDB). |
| Технические требования CMS | |
| ОС | Windows 11/10, Ubuntu 22.04/20.4 (Зависимость для Ubuntu: на целевой системе должны быть установлены утилиты nvidia-smi и sensors). |
| Веб-браузеры | Mozilla Firefox, Google Chrome, Chromium, Apple Safari, Microsoft Edge (Внимание: Internet Explorer 11 не поддерживается) |
| Жесткий диск | 300 МБ |
| версия прошивки контроллера | 1.0.6 или более поздняя версия |
| Версия платы контроллера | 2.xx.xx |
Проектирование, сборка и плотность размещения графических процессоров.
Компоновка и развертывание шасси
Сервер Grando — это образец оптимизации пространства, его размеры составляют 17,3 x 26,8 x 6,97 дюймов (4U). В отличие от традиционных серверов, в нем задняя часть материнской платы расположена спереди корпуса, что переворачивает традиционную внутреннюю компоновку. Это гарантирует, что компоненты с воздушным охлаждением, такие как модули оперативной памяти и VRM, получают максимально холодный воздух до того, как он достигнет радиатора жидкостного охлаждения сзади.
Сам корпус изготовлен в соответствии с теми же высокими стандартами, отличаясь прочной стальной конструкцией с матовым черным порошковым покрытием внутри и снаружи. Этот продуманный выбор распространяется на трубки, кабели, радиатор и защитную маску для печатной платы, отражая явное стремление к чистому, профессиональному внешнему виду. Кроме того, система поддерживает универсальное развертывание, безупречно работая как в качестве 19-дюймового стоечного блока, так и в качестве автономного настольного устройства. В зависимости от конфигурации, ее вес составляет от 148 до 159 фунтов.

Пластины для охлаждения графических процессоров и водоблоки
Фирменные медные водоблоки составляют основу системы охлаждения Grando, охлаждая не только графический процессор, но и другие компоненты, такие как память и регуляторы напряжения. Каждый графический процессор поставляется в виде готовой карты, на которую Comino устанавливает специальную охлаждающую пластину. На практике такая тонкопрофильная конструкция уменьшает размер каждой карты до одного слота, позволяя разместить шесть или даже восемь профессиональных графических процессоров рядом в одном корпусе форм-фактора 4U. В нашем тестовом образце было восемь видеокарт NVIDIA RTX PRO 6000 Blackwell, каждая с TDP 600 Вт, что в сумме дало потребность в охлаждении в 4800 Вт при полной нагрузке.

Достичь плотности размещения 8 видеокарт в одном слоте, как у Comino, было бы практически невозможно с воздушным охлаждением, поскольку стандартные карты NVIDIA RTX PRO 6000 занимают по два слота каждая и требуют значительного воздушного потока. В отличие от них, эти карты с кастомным охлаждением занимают всего один слот каждая. Холодильные пластины сделаны прочно, заметно увеличивая вес каждой карты, но этот вес отражает качество и производительность охлаждения, необходимые на этом уровне.
Каждая пара графических процессоров подключена через отдельный вспомогательный коллектор, который объединяет обе карты в одно входное и выходное соединение с основным коллектором системы охлаждения. Такой парный подход упрощает общую архитектуру контура, уменьшает количество соединений на основном коллекторе и позволяет специалисту отсоединить одну пару быстроразъемных соединений для снятия двух карт одновременно, что еще больше упрощает техническое обслуживание.

Водораспределительная система и коллектор
В центре системы находится большой распределительный коллектор, подающий охлаждающую жидкость к каждой охлаждающей пластине видеокарты и процессора, а также обеспечивающий обратный путь к радиатору. Все соединения между коллектором и видеокартами и процессорами выполнены с использованием быстроразъемных соединений Comino «TheQ». Эти герметичные фитинги из нержавеющей стали имеют цветовую маркировку в виде красных и синих колец для четкой идентификации горячей и холодной сторон контура, что исключает любую двусмысленность при установке или обслуживании.

При отсоединении они оставляют минимальное количество следов на сопрягаемой поверхности, что позволяет техническим специалистам снимать или заменять отдельные графические процессоры или центральный процессор, не сливая жидкость из 450-миллилитрового резервуара или остальной части контура. Таким образом, Grando переносит простоту обслуживания систем воздушного охлаждения на высокопроизводительную платформу жидкостного охлаждения.
Охлаждение процессора и памяти
Процессор и его регуляторы напряжения также выигрывают от использования специальной охлаждающей пластины, подключенной непосредственно к контуру охлаждения, что предотвращает превращение процессора в узкое место при интенсивных нагрузках на несколько графических процессоров. В нашем тестовом образце использовалась материнская плата AMD Turin/Genoa с одним 48-ядерным процессором AMD EPYC 9474F. Охлаждающая пластина по качеству аналогична охлаждающим пластинам видеокарт: она изготовлена из цельной меди и закреплена крепежными элементами из нержавеющей стали.

По бокам от процессора расположены восемь полностью заполненных слотов DRAM, поддерживающих конфигурации до 2 ТБ оперативной памяти. Наш тестовый образец был оснащен 512 ГБ оперативной памяти DDR5. Над областью графического процессора и центрального процессора, перпендикулярно им, проходит поддерживающая планка, которая фиксирует чувствительные компоненты, такие как графический процессор, и обеспечивает жесткость корпуса во время транспортировки.
Радиатор и вентиляторы
Охлаждение обеспечивается большим тройным 140-мм радиатором, установленным в задней части корпуса, в паре с тремя высокоскоростными 140-мм вентиляторами, способными развивать скорость до 6200 об/мин и обеспечивать воздушный поток до 1000 м³/ч. Плотная структура ребер, обеспечиваемая толстым радиатором, подчеркивает тепловой запас, заложенный в конструкцию платформы, которая в нашей конфигурации рассчитана на рассеивание до 6,5 кВт постоянного тепла.
Пожалуй, наиболее удивительно то, что, несмотря на такую нагрузку и скорость вращения вентиляторов, устройство умудряется оставаться в пределах допустимого уровня шума, достигая более 70 дБ на полной мощности. Это громко по меркам рабочих станций, но заметно сдержанно для системы, рассеивающей тепло, сравнимое с небольшой электрической печью, что говорит об эффективности жидкостного контура Comino в отводе тепла от компонентов.

Передняя панель и телеметрический дисплей
На передней панели расположен светодиодный дисплей, отображающий в режиме реального времени ключевые телеметрические данные, включая состояние насоса, температуру окружающего воздуха, температуру охлаждающей жидкости и скорость вращения вентилятора. Пользователи перемещаются по меню с помощью подсвечиваемых кнопок на модуле охлаждения; короткие нажатия позволяют прокручивать доступные данные. Длительное нажатие кнопки PB2 открывает дополнительные разделы меню, включая «Команды», «Настройки обслуживания» и «Журнал событий». Кроме того, на передней панели ввода/вывода расположен порт VGA для вывода изображения, а также последовательный порт, несколько портов USB и сетевые разъемы для подключения периферийных устройств и других устройств.

Архитектура электропитания и хранения энергии
Подача питания и резервирование
Для поддержки такого уровня вычислительной мощности требуется столь же надежная система электропитания. Grando поддерживает до четырех модулей CRPS мощностью 1000 Вт или 2000 Вт с возможностью горячей замены в резервной конфигурации, обеспечивая мощность до 8 кВт при напряжении 180–264 В. Благодаря поддержке режимов резервирования 4+0, 3+1 и 2+2 система может выдерживать отказы блока питания, обеспечивая непрерывную работу для круглосуточных задач искусственного интеллекта и высокопроизводительных вычислений.

В комплект нашего тестового образца входили четыре блока питания Great Wall 2000W 80 Plus Platinum с возможностью горячей замены, что составляло полную конфигурацию мощностью 8,0 кВт.

Питание каждого графического процессора осуществляется через централизованную 12-контактную плату распределения питания, установленную между массивом графических процессоров и основным кабельным каналом. Grando использует эту плату распределения для консолидации входящих сигналов питания и последующего их распределения к каждому графическому процессору организованным и компактным способом.

PCIe, хранение данных и сети
Корпус Grando с комфортом поддерживает шесть видеокарт без ущерба для пропускной способности слотов, а его возможности масштабируются до конфигурации с восемью видеокартами для максимальной плотности размещения. Материнская плата ASRock Rack GENOAD8X-2T/BCM от Comino обеспечивает семь слотов x16 и один слот x8 PCIe Gen 5, что означает, что семь из восьми видеокарт работают с полной пропускной способностью x16, а восьмая карта — с пропускной способностью x8. Это компромисс между количеством линий PCIe, которые может поддерживать односокетный процессор, и нежеланием Comino добавлять размер, стоимость и сложность платы переключения PCIe. Переход на двухсокетную материнскую плату обеспечил бы больше линий PCIe, но предложил бы еще меньше слотов, поскольку второй сокет занял бы место, которое в ограниченном пространстве занимали бы слоты PCIe.

Запуск восьми графических процессоров в односокетной системе потребляет львиную долю доступных линий PCIe, что влечет за собой определенные компромиссы. В нашем тестовом образце на базе AMD Genoa доступно в общей сложности 128 линий PCIe Gen 5. При восьми графических процессорах, занимающих 120 из этих линий, оставшиеся 8 линий распределяются по четырем слотам M.2 SSD, поэтому невозможно одновременно запустить восемь графических процессоров и полный комплект NVMe-накопителей в задней части корпуса, подключенных через два разъема MCIO. В нашей полной конфигурации с 8 графическими процессорами для хранения данных было доступно только 2 слота M.2. Администраторам, которым требуется дополнительная емкость NVMe наряду с максимальной плотностью графических процессоров, следует учитывать, что добавление NVMe-накопителей с возможностью горячей замены через задние корзины на задней панели приведет к потреблению дополнительных линий PCIe и отключению части графических процессоров в системе.
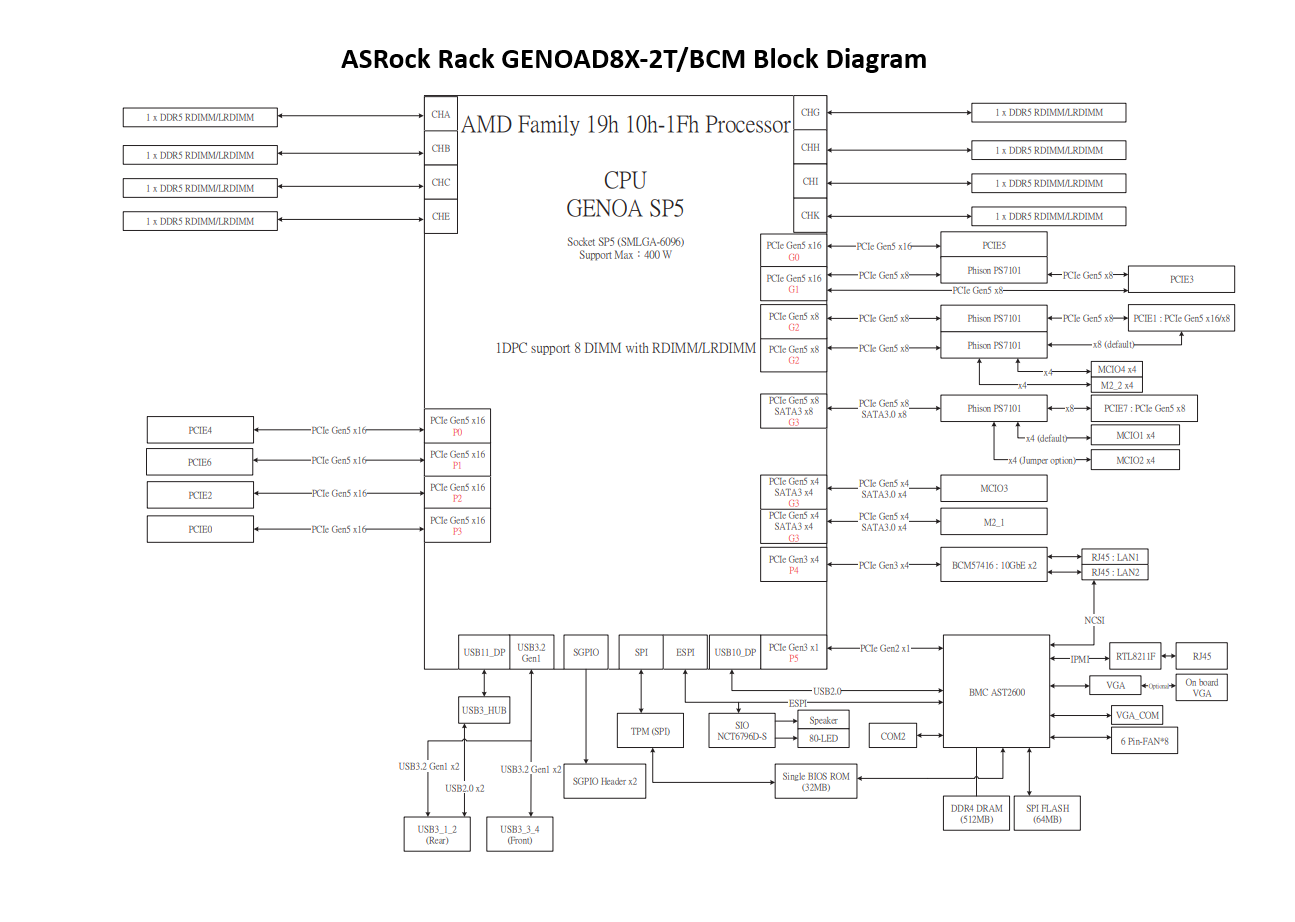
Блок-схема материнской платы ASRock Rack GENOAD8X-2T/BCM, показывающая расположение процессора, слотов PCIe Gen 5, каналов DIMM, слотов M.2, BMC, USB, SATA и сетевых разъемов.
При этом система хранения данных также модульная и широкая, хотя конфигурация влияет на бюджет линий PCIe для видеокарт, что стоит учитывать при планировании предполагаемого использования. На задней панели нашего тестового образца расположена корзина для 2,5-дюймовых накопителей, поддерживающая до четырех 2,5-дюймовых SSD-накопителей в конфигурациях 4x7 мм или 2x15 мм, с возможностью установки второго комплекта до четырех накопителей вместо четвертого слота блока питания. Поскольку для поддержки полной конфигурации из 8 видеокарт нашему тестовому образцу требовались все четыре отсека для блоков питания, у нас был доступ только к первому из двух отсеков с возможностью горячей замены. Внутри корпуса может быть установлена корзина для 3,5-дюймовых накопителей, вмещающая до четырех 3,5-дюймовых накопителей, четыре 2,5-дюймовых накопителя 15 мм или до двенадцати 2,5-дюймовых накопителей 7 мм, а также четыре дополнительных внутренних слота для 2,5-дюймовых SSD-накопителей 7 мм, если это предусмотрено конфигурацией.

Для подключения к сети на материнской плате стандартно установлены два порта RJ45 10 Гбит/с на базе Broadcom BCM57416, а также выделенный порт управления Gigabit Ethernet IPMI. Администраторы могут дополнительно увеличить пропускную способность, установив сетевые карты PCIe, поддерживающие скорость до 400 Гбит/с для высокоскоростного подключения к сети, однако следует отметить, что дополнительные сетевые карты PCIe занимают слоты для видеокарт, уменьшая максимальное количество видеокарт, которые может разместить система.

Удаленное управление и системный интеллект
Для защиты оборудования и оптимизации производительности система включает в себя систему мониторинга Comino (CMS). Отдельная автономная плата управления управляет CMS и служит «мозгом» сервера, независимым от основной операционной системы. На практике этот контроллер считывает данные с широкого спектра датчиков, отслеживающих температуру воздуха и охлаждающей жидкости, уровень влажности, расход охлаждающей жидкости и уровень жидкости в резервуаре в режиме реального времени. Что особенно важно, такая автономная конструкция позволяет CMS проводить самодиагностику и запускать аварийные отключения при обнаружении утечки или отказа насоса, защищая дорогостоящее внутреннее оборудование от повреждений.
Веб-интерфейс пользователя (GUI) обеспечивает ежедневное управление, предоставляя администраторам четкое представление о производительности системы охлаждения, времени безотказной работы и потреблении энергии в режиме реального времени процессором и видеокартами. Для корпоративных развертываний CMS также подключается к централизованным инструментам мониторинга через REST API, таким как Zabbix, Grafana и InfluxDB. В совокупности эти возможности помогают администраторам поддерживать трехлетний межсервисный интервал и обеспечивать работу сервера с максимальной эффективностью без перегрева, даже в условиях высоких температур окружающей среды.
За пределами ИИ: творческие и инженерные приложения.
Хотя наше тестирование было сосредоточено на задачах вывода ИИ, Grando также может быть полезен для творческих специалистов и инженеров, которым необходимы значительные локальные вычислительные мощности графического процессора. 768 ГБ суммарной видеопамяти на восьми картах RTX PRO 6000 открывают возможности, недоступные в обычных рабочих станциях.
Специалисты по спецэффектам и моушн-графике могут рендерить сложные сцены с огромными наборами текстур полностью в видеопамяти, устраняя проблемы, связанные с подкачкой дисков, которые преследуют проекты, использующие 8K-видео или высокополигональные среды. Инженеры САПР, занимающиеся вычислительной гидродинамикой или моделированием конструкций, могут работать со сборками беспрецедентной сложности, не разделяя свои модели на несколько этапов. Видеоредакторы, работающие с многопотоковыми 8K RAW-таймлайнами, колористы, применяющие шумоподавление на основе машинного обучения в полном разрешении, и 3D-художники, рендерящие финальные изображения с трассировкой лучей локально, а не ожидая доступности облачной фермы, — все они получают выгоду от такой плотности памяти и вычислительных ресурсов графического процессора.
Для Grando не требуется полноценная конфигурация с восемью графическими процессорами. Comino предлагает платформу в конфигурациях с четырьмя, шестью и восемью графическими процессорами, причем все варианты доступны для немедленной поставки. Небольшие студии, независимые разработчики и инженерные команды могут оптимизировать свои инвестиции в соответствии с текущими потребностями, сохраняя при этом четкий путь обновления по мере роста рабочих нагрузок.
Компромиссы между платформами: плотность размещения и расширяемость
Компактная конструкция Grando обеспечивает исключительную плотность размещения графических процессоров и эффективное управление теплоотводом в стандартном форм-факторе 4U, однако такая плотность влечет за собой архитектурные компромиссы, которые стоит учитывать перед развертыванием.
Корпус подходит для материнских плат форм-факторов EATX и EEB, но не для расширенных серверных плат, используемых в традиционных двухсокетных платформах. Это ограничивает общее количество доступных линий PCIe для периферийных устройств, помимо графического процессора. В нашей конфигурации с восемью графическими процессорами 128 линий PCIe Gen 5 процессора AMD EPYC почти полностью заняты графическими процессорами, оставляя мало пропускной способности для дополнительного хранилища NVMe или высокоскоростной сети, помимо встроенных портов 10GbE.
Это контрастирует с платформами с восемью графическими процессорами, которые мы рассматривали у Dell, HPE и Supermicro. В этих системах используются более крупные корпуса, двухсокетные конфигурации и топологии коммутаторов PCIe для поддержки значительно большего количества периферийных устройств. Обычно они вмещают от четырех до восьми дополнительных сетевых адаптеров или DPU в дополнение к полному набору графических процессоров, а также восемь или более отсеков NVMe с возможностью горячей замены, что делает их хорошо подходящими для распределенных задач вывода, требующих высокоскоростных межсоединений.
Однако расширение возможностей сопряжено со значительными затратами. Потребляемая мощность превышает 8 кВт. Тепловые нагрузки требуют наличия специализированной инфраструктуры охлаждения для центров обработки данных. Высокий уровень шума исключает возможность развертывания за пределами специально оборудованных машинных помещений. А сроки поставки часто растягиваются на шесть-восемнадцать месяцев из-за постоянных ограничений поставок корпоративных платформ графических процессоров.
Grando занимает иную позицию. Для организаций, которые отдают приоритет быстрому развертыванию, управляемым операционным средам и задачам вывода или творческой работе, а не крупномасштабному распределенному обучению, компромиссы часто оказываются выгодными. Команды, которым необходимо оборудование сейчас, в среде, с которой они действительно могут работать, могут найти подход Grando к плотности размещения более практичным, чем ожидание в очереди на платформу, которую они не смогут реально развернуть после ее поступления.
Результаты тестирования производительности Comino Grando

Конфигурация системы
- Шасси: Комино Грандо
- Материнская плата: ASRock Rack GENOAD8X-2T/BCM
- Процессор: AMD EPYC 9474F 48C
- Память: 512 ГБ DDR5
- Видеокарты: 8 x NVIDIA RTX PRO 6000
- Хранение данных: M.2 SSD
Сервировочная машина Claude Code Serving – MiniMax M2.5
Помимо традиционных тестов производительности LLM-вычислений, мы хотели оценить, насколько хорошо это оборудование работает в процессе агентного программирования, в частности, при одновременном запуске нескольких сессий Claude Code с использованием локально размещенной модели. Этот сценарий напрямую связан с производительностью команды разработчиков: сколько инженеров могут одновременно использовать помощника по программированию на основе ИИ, запущенного с одного узла, прежде чем качество работы ухудшится?
Для проверки этого мы создали тестовую среду, которая генерирует набор данных из задач программирования средней сложности (таких как реализация LRU-кэша, создание приложения для управления задачами в командной строке, написание конвертера Markdown и разработка REST API) и запускает каждую сессию Claude Code в отдельном контейнере Docker с использованием локального сервера vLLM. Между сессиями и конечной точкой вывода находится прозрачный прокси-сервер, который собирает метрики для каждого запроса в каждом экземпляре Claude Code. Использовалась модель MiniMax M2.5, работающая через vLLM на восьми графических процессорах NVIDIA RTX PRO 6000. Хотя M2.5 не является лучшей моделью программирования в публичных рейтингах, это мощная модель, которую многие пользователи, включая наших друзей-разработчиков, запускают локально.
В качестве базового показателя мы используем среднюю пропускную способность Anthropic Claude Opus 4.6, полученную через OpenRouter.ai, один из самых популярных сервисов маршрутизации для доступа к API в производственной среде. Этот базовый показатель составляет приблизительно 37 токенов в секунду на один запрос к API.
Мы измерили два ключевых показателя: среднее количество токенов, обрабатываемых в секунду за сессию Claude Code (то, что обрабатывает каждый разработчик), и совокупное количество токенов, обрабатываемых в секунду по всем сессиям (общий объем работы, выполняемой сервером).
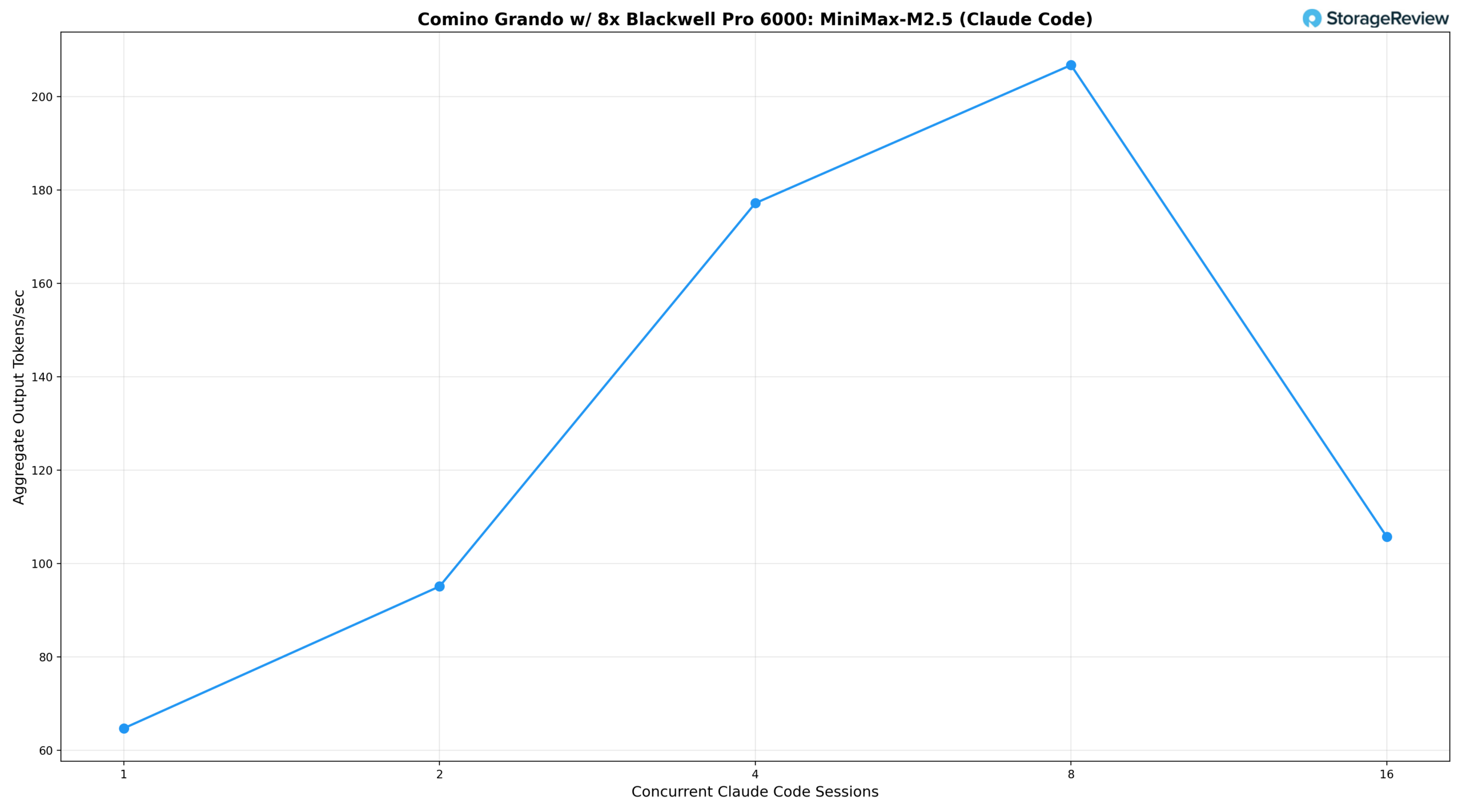
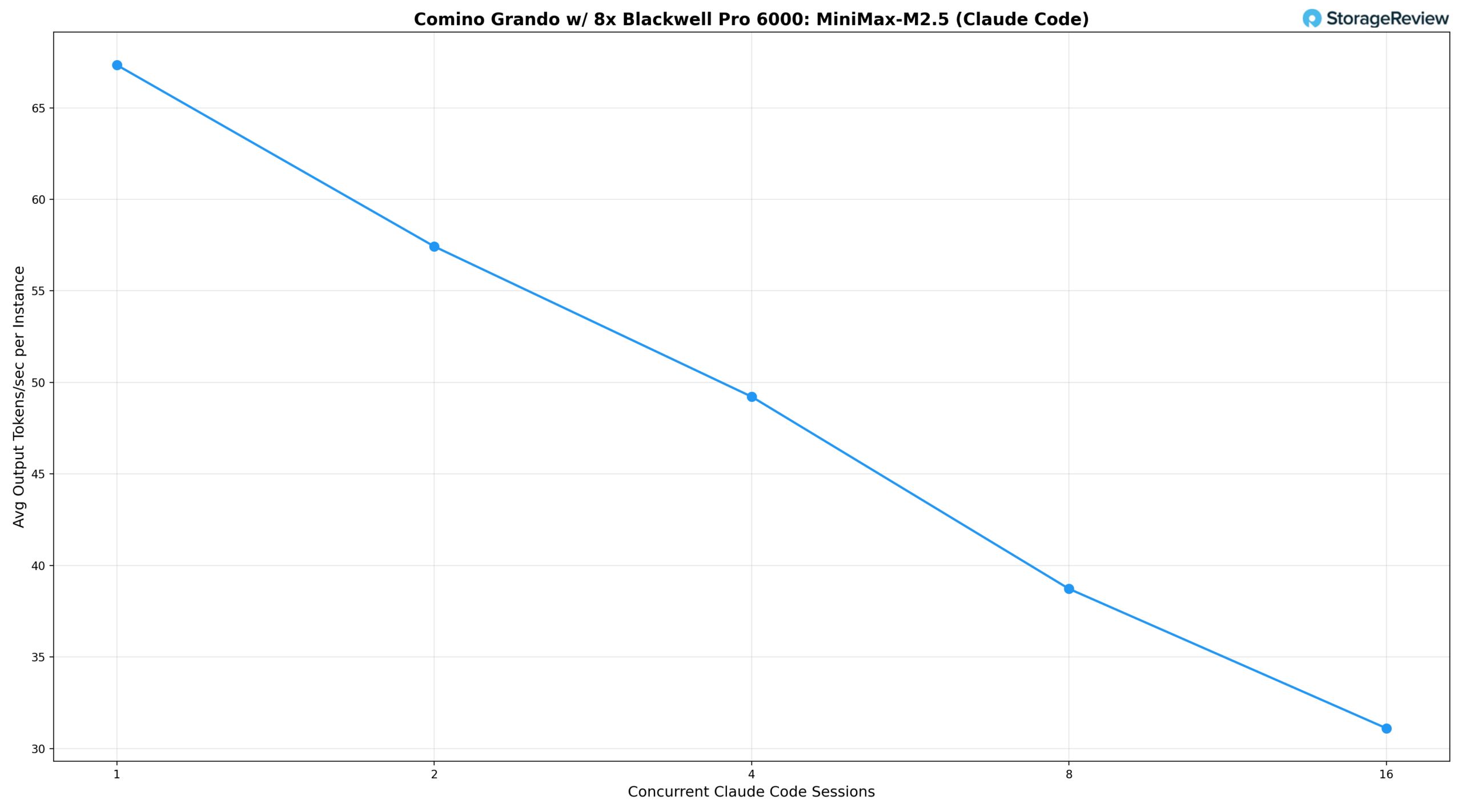
Согласно результатам, одна одновременная сессия Claude Code обеспечивает 67,3 токена в секунду на пользователя и совокупный вывод 64,7 токена в секунду. При двух сессиях пропускная способность на экземпляр незначительно снижается до 57,4 токена в секунду, в то время как совокупный вывод увеличивается до 95,1 токена в секунду, поскольку пакетная обработка vLLM начинает амортизировать накладные расходы. Четыре одновременные сессии поддерживают 49,2 токена в секунду на пользователя, что по-прежнему обеспечивает высокую скорость отклика для интерактивных рабочих процессов программирования, в то время как совокупная пропускная способность достигает 177,2 токена в секунду. Восемь сессий представляют собой оптимальный уровень совокупного вывода, достигая пика в 206,7 токена в секунду, в то время как пропускная способность на экземпляр стабилизируется на уровне 38,7 токена в секунду, что остается комфортным для генерации и итерации кода в реальном времени.
При 16 одновременных сессиях система демонстрирует классический компромисс пакетной обработки: пропускная способность на один экземпляр падает до 31,1 ток/с, а совокупная производительность снижается до 105,8 ток/с. Это говорит о том, что при таком уровне параллелизма модель 230B MiniMax M2.5 работает на пределе возможностей восьми графических процессоров без существенной задержки для каждого пользователя. Совокупное падение производительности при переходе от 8 к 16 сессиям отражает потребности в пропускной способности памяти большой архитектуры MoE при высокой одновременной нагрузке на декодирование, а не неэффективность планирования.
Для организаций, оценивающих возможность создания собственной инфраструктуры ИИ для инструментов разработчиков, Grando представляет собой убедительный вариант. Используя модель Frontier 230B, он может с комфортом обслуживать до восьми одновременных сессий Claude Code с уровнем пропускной способности, обеспечивающим по-настоящему интерактивное взаимодействие, при этом скорость на пользователя превышает 38 ток/с при пиковой суммарной нагрузке. Команды из четырех-восьми инженеров могут работать с почти оптимальной пропускной способностью без заметного снижения скорости отклика.
Архитектура с жидкостным охлаждением также делает такой уровень вычислительной мощности практичным в средах, где традиционные серверы с графическими процессорами не могут работать. Система работает достаточно тихо, чтобы разместиться в офисе стартапа, небольшом машинном зале или специально отведенном уголке открытого рабочего пространства. Системы с воздушным охлаждением и аналогичной плотностью графических процессоров обычно достигают уровня шума 90 дБ и выше, что достаточно громко, чтобы потребовать выделенного места в центре обработки данных или, как минимум, закрытого серверного шкафа с серьезной звукоизоляцией. Grando может сосуществовать с командой, которая его использует. В сочетании с полной локализацией данных, отсутствием платы за API за каждый токен и полным контролем над выбором модели, он предлагает самодостаточный путь, масштабируемый по мере роста команды разработчиков без необходимости в инфраструктуре центра обработки данных или ступенчатого увеличения затрат.
Онлайн-сервис vLLM – Производительность вывода данных LLM
vLLM — один из самых популярных высокопроизводительных механизмов вывода и обслуживания для LLM-систем. Онлайн-бенчмарк vLLM оценивает реальную производительность этого механизма вывода при одновременном запросе. Он имитирует производственные нагрузки, отправляя запросы на работающий сервер vLLM с настраиваемыми параметрами, такими как скорость запросов, длина входных и выходных данных, а также количество одновременно работающих клиентов. Бенчмарк измеряет ключевые показатели, включая пропускную способность (токены в секунду), время до получения первого токена и время на один выходной токен (TPOT), помогая пользователям понять, как vLLM работает в различных условиях нагрузки.
Мы протестировали производительность вывода на основе широкого набора моделей, охватывающих различные архитектуры, масштабы параметров и стратегии квантования, чтобы оценить пропускную способность при различных профилях параллельного выполнения.
Краткое изложение результатов
| Модель | Точность | Равно (256/256) | Предварительно заполняемый (8k/1k) | Интенсивное декодирование (1k/8k) |
|---|---|---|---|---|
| Comino Grando с 8 видеокартами RTX PRO 6000 Blackwell — результаты вывода vLLM (ток/с, пиковое значение на BS=256) | ||||
| GPT-OSS 20B | ep_dp1 | 17,280 | 32,061 | 11,187 |
| GPT-OSS 120B | ep_dp1 | 11,726 | 21,636 | 7570 |
| Лама 3.1 8B Инструкция | FP8 | 12,109 | 20,137 | 7353 |
| Лама 3.1 8B Инструкция | FP4 | 11,954 | 20,206 | 7,239 |
| Лама 3.1 8B Инструкция | БФ16 | 11,752 | 17,346 | 6,155 |
| Qwen3 Coder 30B A3B | FP8 | 10,985 | 16,659 | 4907 |
| Qwen3 Coder 30B A3B | БФ16 | 10,588 | 16,680 | 4,829 |
| Mistral Small 3.1 24B | БФ16 | 8,925 | 11,846 | 4,975 |
| Минимакс М2.5 (230B) | ep_dp1 | 5753 | 7357* | 2555 |
| Все значения указаны в ток/с, пиковая пропускная способность при BS=256. *Машина MiniMax M2.5 с интенсивным предварительным заполнением достигла пиковой пропускной способности при BS=128 (7357 ток/с); при BS=256 — 7141 ток/с. | ||||
GPT-OSS 120B и 20B
Семейство моделей GPT-OSS было протестировано в конфигурациях 120B и 20B на космическом корабле Comino Grando.
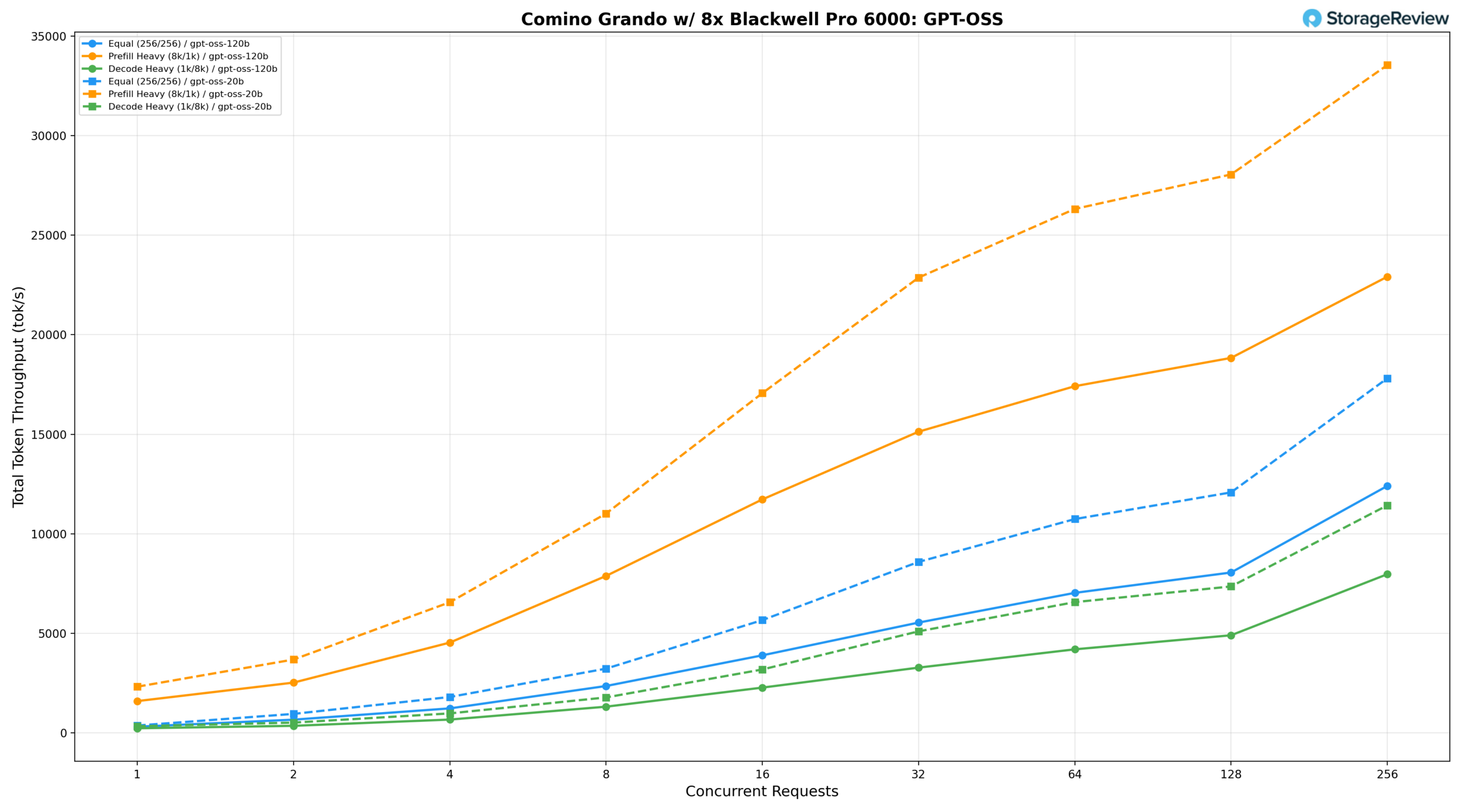
GPT-OSS 120B
При одинаковой нагрузке (256/256) модель 120B обеспечивает производительность 268,85 тонн/с при BS=1, достигает 6666,23 тонн/с при BS=64 и пикового значения 11726,04 тонн/с при BS=256. При интенсивном предварительном заполнении (8 тыс./1 тыс.) производительность начинается с 1375,69 тонн/с, увеличивается до 16374,19 тонн/с при BS=64 и 17944,55 тонн/с при BS=128, и достигает пикового значения 21636,41 тонн/с при BS=256. Интенсивность декодирования (1k/8k) возрастает со 196,28 ток/с при BS=1 до 7569,97 ток/с при BS=256, при этом задержка хорошо контролируется при более низких уровнях параллелизма.
GPT-OSS 20B
Модель 20B обеспечивает производительность 334,80 тонн/с при BS=1 при одинаковой нагрузке, достигает 10 303,56 тонн/с при BS=64 и пикового значения 17 280,12 тонн/с при BS=256. При интенсивном предварительном заполнении производительность начинается с 2007,90 тонн/с, увеличивается до 24 990,46 тонн/с при BS=64 и 26 866,25 тонн/с при BS=128, достигая пика в 32 060,72 тонн/с при BS=256, что является самым высоким абсолютным показателем производительности предварительного заполнения, зарегистрированным для обеих моделей. Скорость декодирования увеличивается с 286,08 ток/с при BS=1 до 11 187,36 ток/с при BS=256, обеспечивая примерно в 1,5 раза большую пропускную способность декодирования по сравнению с 120B при пиковой параллельности, сохраняя при этом более низкую задержку.
Qwen3 Coder 30B A3B Instruct и FP8 Instruct
Модель Qwen3-Coder-30B-A3B-Instruct была протестирована как с точностью BF16, так и с точностью FP8.
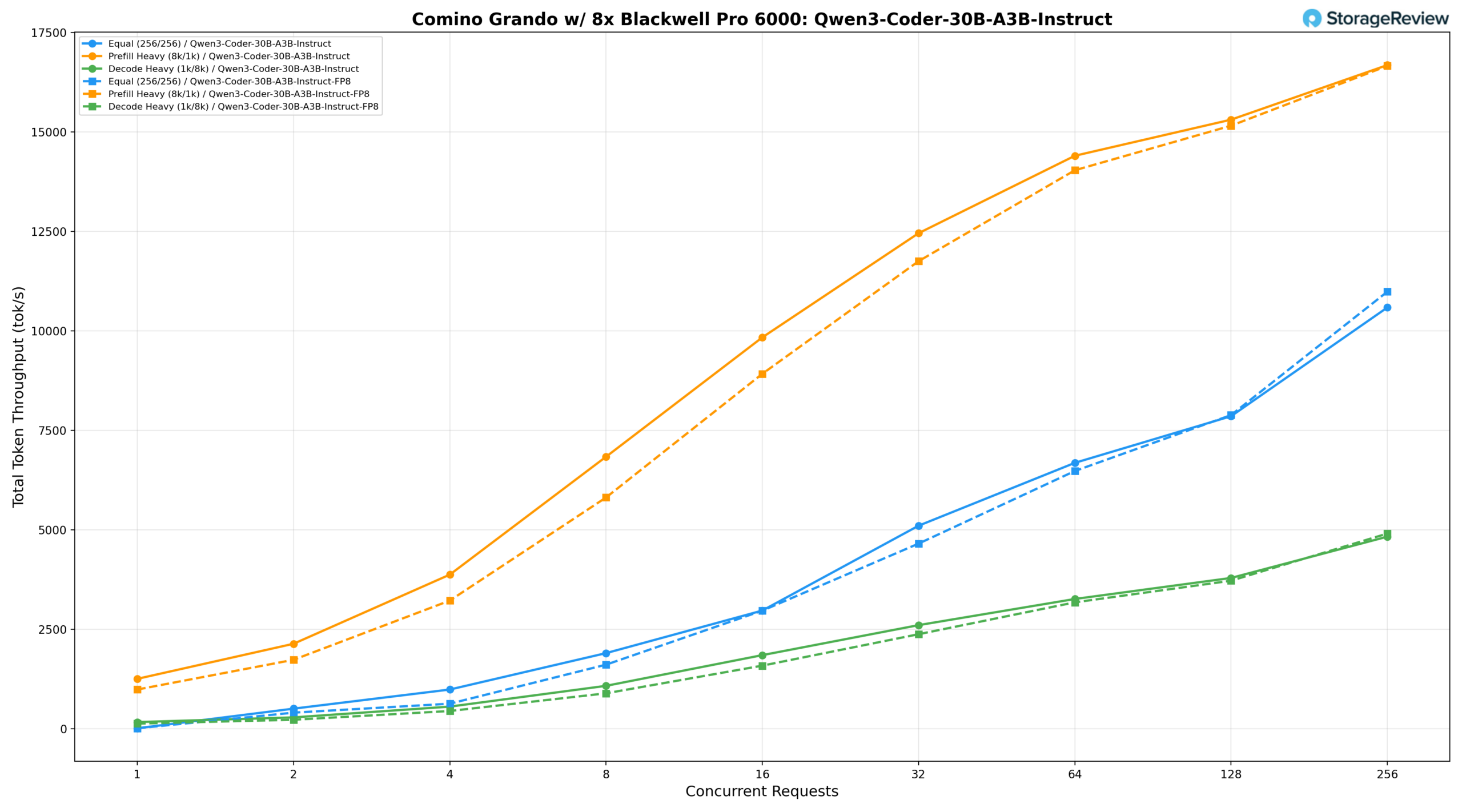
Qwen3-Coder-30B-A3B-Instruct (BF16)
При одинаковой нагрузке (256/256) модель BF16 обеспечивает скорость 1902,32 ток/с при BS=8, достигает 6683,58 ток/с при BS=64 и пикового значения 10587,56 ток/с при BS=256. При интенсивном предварительном заполнении (8 тыс./1 тыс.) скорость начинается с 1256,03 ток/с при BS=1, увеличивается до 14400,57 ток/с при BS=64 и 15308,35 ток/с при BS=128, и достигает пикового значения 16679,52 ток/с при BS=256. Интенсивность декодирования (1k/8k) возрастает со 169,19 ток/с при BS=1 до 4828,82 ток/с при BS=256, при этом задержка хорошо контролируется при более низких уровнях параллелизма.
Qwen3-Coder-30B-A3B-Instruct (FP8)
Модель FP8 обеспечивает пропускную способность, сопоставимую с BF16, в большинстве сценариев, при этом при одинаковой нагрузке она достигает 6478,54 ток/с при BS=64 и пикового значения 10984,61 ток/с при BS=256, что немного превосходит BF16 при пиковой параллелизме. При интенсивном предварительном заполнении пропускная способность начинается с 987,48 ток/с при BS=1, возрастает до 14036,46 ток/с при BS=64 и 15156,69 ток/с при BS=128, и достигает пика в 16658,98 ток/с при BS=256. Скорость декодирования увеличивается со 130,70 ток/с при BS=1 до 4906,51 ток/с при BS=256, незначительно превосходя BF16 по пиковой параллелизм, в то время как в остальном диапазоне параллелизма обе конфигурации остаются практически идентичными.
Mistral Small 3.1 24B Инструкция 2503
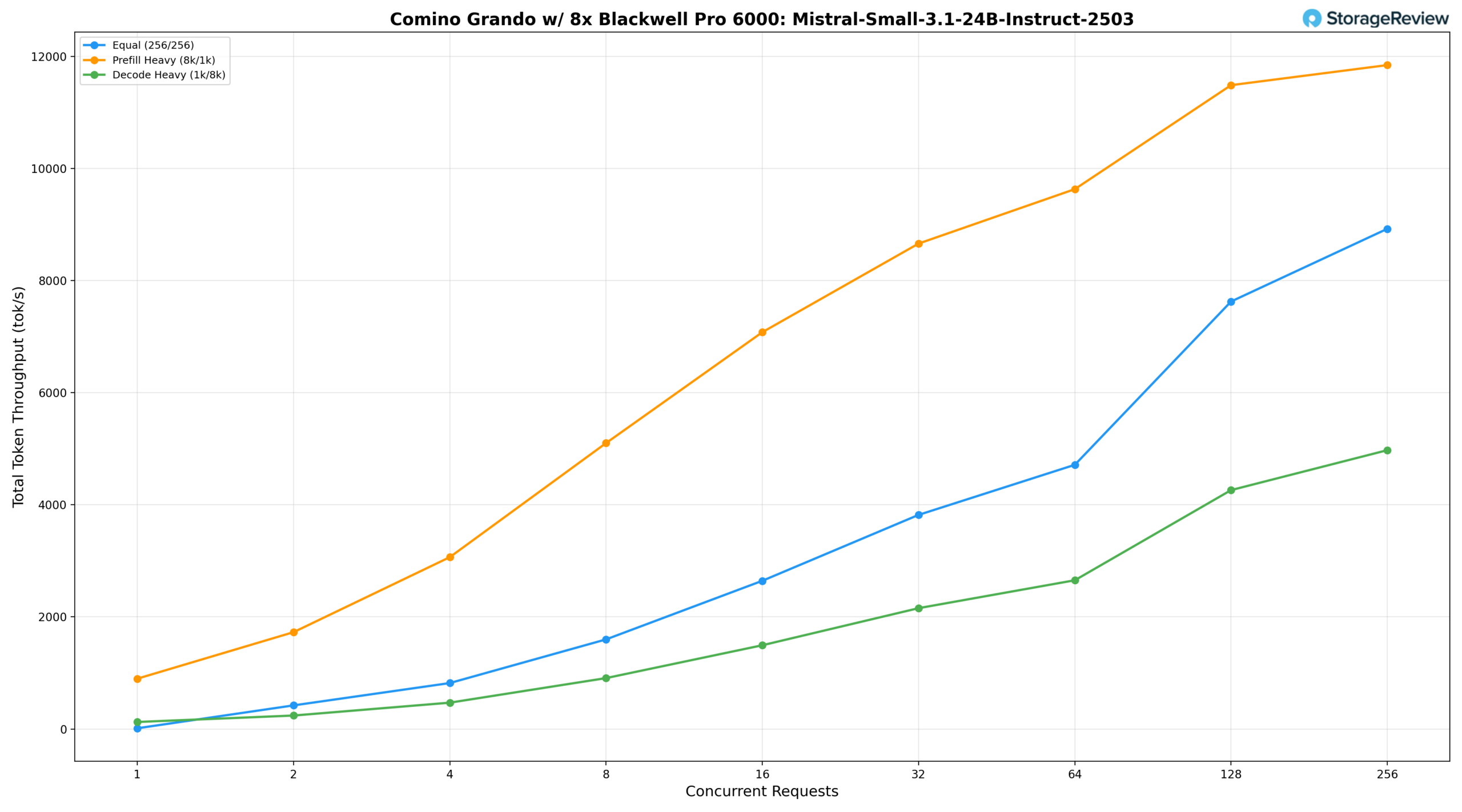
При одинаковой рабочей нагрузке (256/256) модель обеспечивает производительность 1598,79 ток/с при BS=8, достигает 4713,84 ток/с при BS=64 и резко возрастает до 8925,12 ток/с при BS=256. При интенсивном предварительном заполнении (8k/1k) производительность начинается с 897,84 ток/с при BS=1, возрастает до 9632,58 ток/с при BS=64 и 11488,13 ток/с при BS=128, достигая пика в 11846,15 ток/с при BS=256. Скорость декодирования (1k/8k) возрастает со 124,98 ток/с при BS=1 до 2653,82 ток/с при BS=64, а затем заметно ускоряется при более высоких уровнях параллелизма, достигая 4262,53 ток/с при BS=128 и пикового значения в 4975,06 ток/с при BS=256, что отражает способность модели поддерживать высокую пропускную способность декодирования по мере увеличения параллелизма.
Лама 3.1 8B Инструкция
Модель Llama-3.1-8B-Instruct была протестирована на трех конфигурациях точности на устройстве Comino, что позволило наглядно увидеть, как квантование влияет на пропускную способность для модели такого размера.
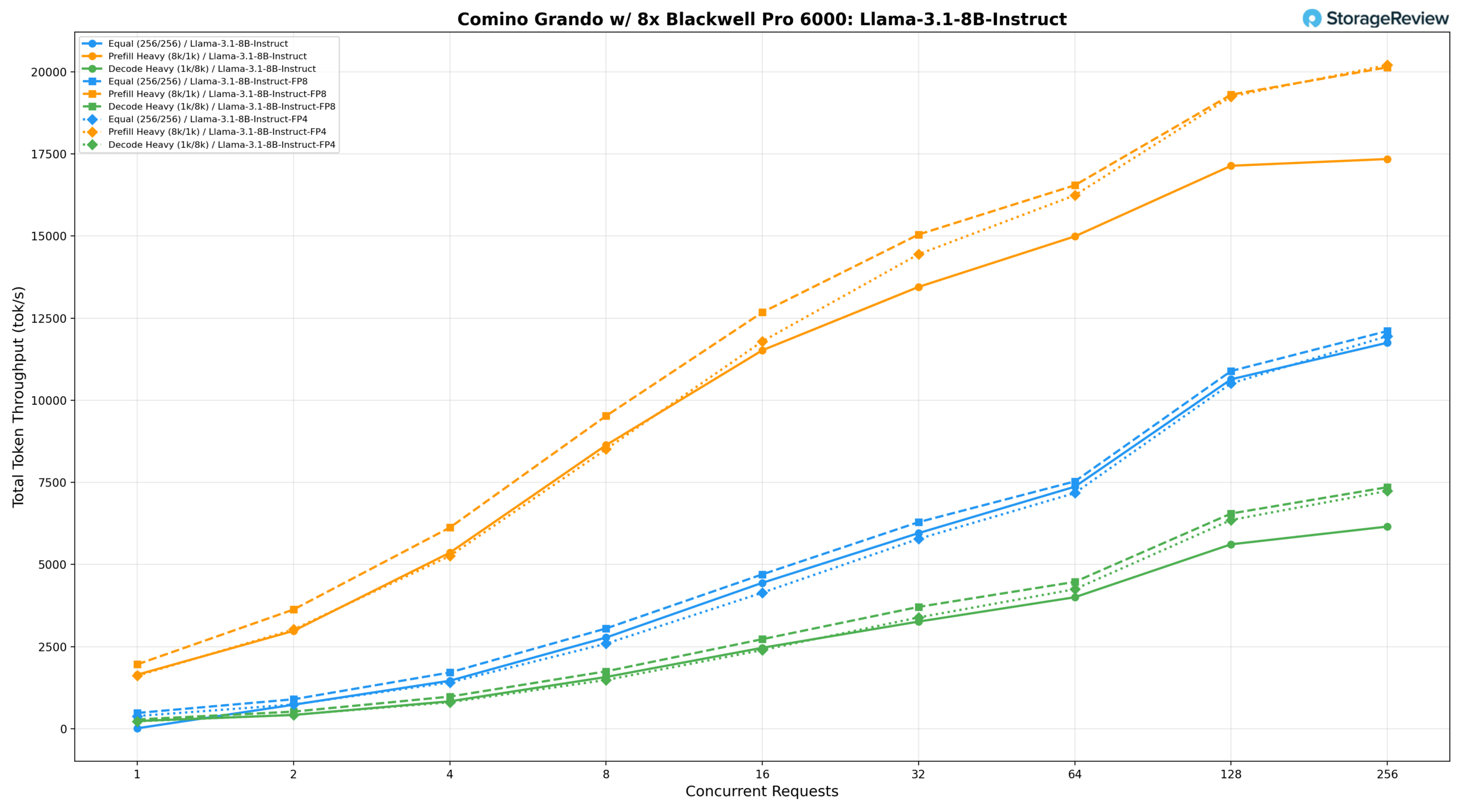
Лама 3.1 8B Инструкция BF16
При одинаковой нагрузке (256/256) модель BF16 обеспечивает скорость 2776,42 тонн/с при BS=8, достигает 7369,01 тонн/с при BS=64 и пикового значения 11751,56 тонн/с при BS=256. При интенсивном предварительном заполнении (8 тыс./1 тыс.) скорость начинается с 1645,29 тонн/с при BS=1, увеличивается до 14990,47 тонн/с при BS=64 и 17140,71 тонн/с при BS=128, и достигает пикового значения 17345,80 тонн/с при BS=256. Скорость декодирования (1k/8k) возрастает с 234,78 ток/с при BS=1 до 6154,73 ток/с при BS=256.
Лама 3.1 8B Инструкция FP8
Квантование FP8 обеспечивает существенное улучшение во всех сценариях. При одинаковой рабочей нагрузке производительность достигает 7530,39 ток/с при BS=64 и пикового значения 12108,98 ток/с при BS=256. При интенсивном предварительном заполнении производительность возрастает до 16546,53 ток/с при BS=64 и 19306,49 ток/с при BS=128, достигая пикового значения 20137,35 ток/с при BS=256, что примерно на 16% больше, чем при BF16 в пиковой параллельности. При интенсивном декодировании пиковая производительность достигает 7353,40 ток/с при BS=256, что примерно на 19% выше, чем при BF16.
Лама 3.1 8B Инструкция FP4
FP4 обеспечивает пропускную способность, близкую к FP8 при более высоких уровнях параллелизма, хотя немного отстает при меньших размерах пакетов. При одинаковой нагрузке пиковая производительность составляет 11 954,40 ток/с при BS=256, а при интенсивном предварительном заполнении — 20 205,57 ток/с при BS=256, немного превосходя FP8 по пиковой параллелизму. При интенсивном декодировании пиковая производительность составляет 7 239,29 ток/с при BS=256, оставаясь в пределах нескольких процентов от FP8 на протяжении всего процесса, что делает FP4 привлекательным вариантом, когда приоритетом является эффективность использования памяти без существенного снижения пропускной способности.
Минимакс М2.5
Модель MiniMax-M2.5 230B, протестированная на велосипеде Comino Grando, оказалась самой крупной и требовательной к ресурсам из всех, что мы использовали.
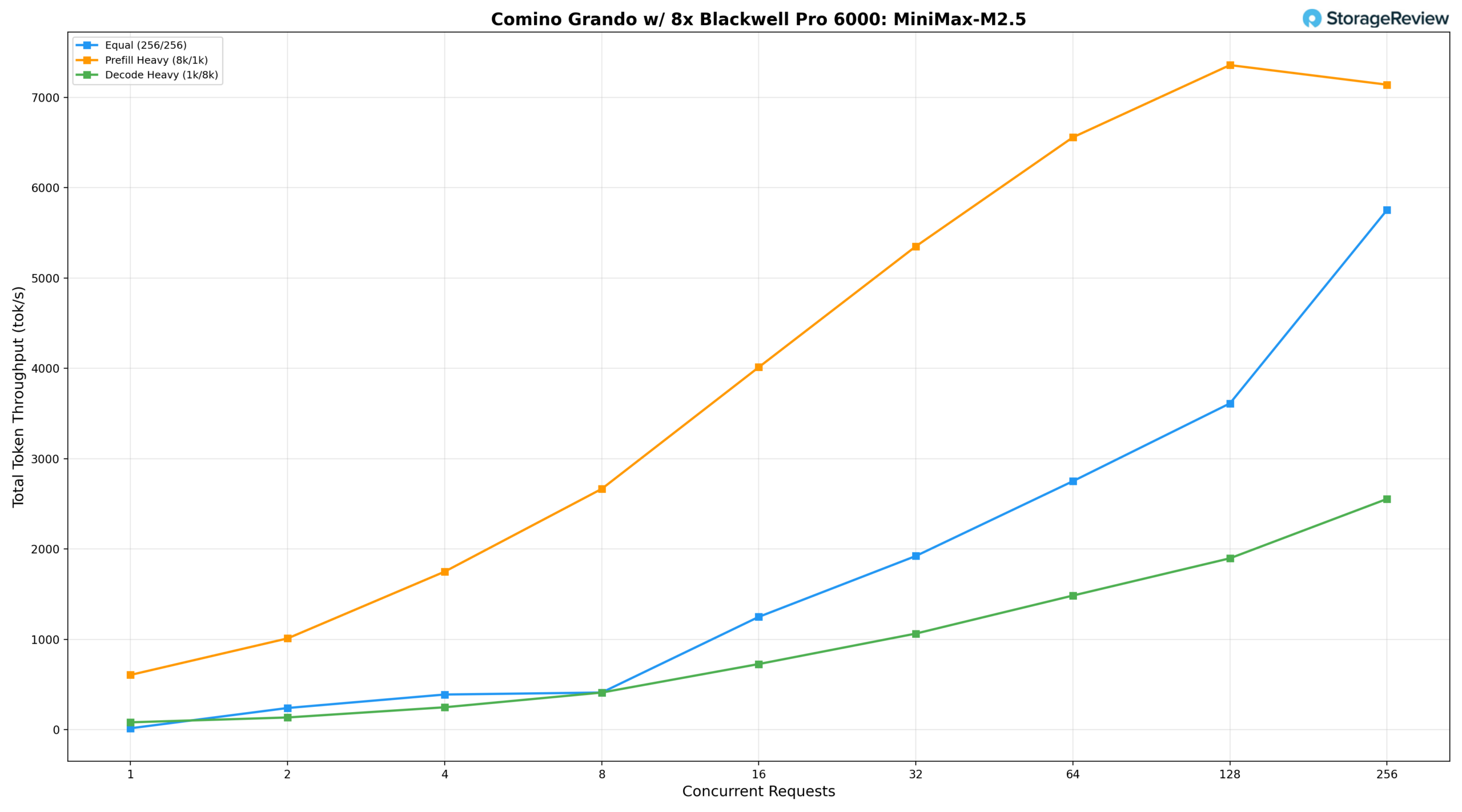
При одинаковой рабочей нагрузке (256/256) модель начинает работу с производительностью 16,35 ток/с при BS=1, достигает 2751,25 ток/с при BS=64 и резко возрастает при более высокой параллелизме, достигая пика в 5753,24 ток/с при BS=256. При интенсивном предварительном заполнении (8 тыс./1 тыс.) производительность начинается с 606,97 ток/с при BS=1, неуклонно возрастает до 5351,02 ток/с при BS=32 и 6557,92 ток/с при BS=64, достигая пика в 7357,26 ток/с при BS=128, после чего немного снижается до 7140,74 ток/с при BS=256, что указывает на приближение модели к насыщению по пропускной способности предварительного заполнения при BS=128. Интенсивность декодирования (1k/8k) стабильно возрастает с 82,21 ток/с при BS=1 до 1485,28 ток/с при BS=64, достигая пика в 2554,87 ток/с при BS=256, что отражает ожидаемые требования к пропускной способности памяти 230-битной архитектуры MoE при длительных нагрузках декодирования.
Заключение
Comino Grando лучше всего понимать как систему, специально разработанную для раскрытия всего потенциала восьми графических процессоров NVIDIA RTX PRO 6000. Каждое важное конструктивное решение, от инвертированной компоновки материнской платы до системы охлаждения и интегрированного блока мониторинга, призвано обеспечить непрерывную работу этих графических процессоров при полной мощности 600 Вт без перегрева или ограничений по энергопотреблению.

Привлекательность Grando заключается не в какой-либо отдельной функции, а в том, как вся система работает вместе. Жидкостное охлаждение — это не просто дополнительная опция, а часть архитектуры. Система питания резервирована, допускает «горячую» замену и масштабирована до нагрузки в 4800 Вт, создаваемой восемью картами по 600 Вт, с запасом мощности. Система мониторинга выходит за рамки простого отображения температуры; она автоматически защищает оборудование в случае возникновения неполадок. Ничто здесь не выглядит как нечто второстепенное.
Показатели производительности подтверждают эту согласованность. В различных моделях, от Llama 3.1 8B до 230B MiniMax M2.5, Grando продемонстрировал показатели пропускной способности, которые хорошо себя зарекомендовали для платформы с самостоятельным размещением. Тестирование параллельной обработки данных с помощью Claude Code еще раз подтвердило практическую ценность: восемь инженеров могут одновременно запускать сеансы агентного программирования на локально размещенной модели 230B на интерактивных скоростях, при этом пропускная способность на пользователя превышает 38 ток/с при пиковой суммарной производительности. Команды из четырех-восьми человек могут работать с почти оптимальной пропускной способностью без заметного снижения производительности.
Ценность этой конфигурации выходит за рамки задач искусственного интеллекта. Благодаря 96 ГБ видеопамяти на каждый графический процессор и высокой плотности масштабирования на нескольких графических процессорах, платформа одинаково хорошо подходит для высокопроизводительных творческих и инженерных задач, включая рендеринг визуальных эффектов, крупномасштабное моделирование и сложные конвейеры САПР. Система масштабируется до конфигураций с четырьмя и двумя графическими процессорами, что делает этот уровень производительности доступным для небольших студий и команд, которым по-прежнему требуется высокая производительность, характерная для рабочих станций.
Главное отличие Grando от рассмотренных нами корпоративных платформ с восемью графическими процессорами заключается в практичности развертывания. Эти системы предлагают больше линий PCIe, больше слотов для сетевых карт и более широкие возможности подключения хранилищ, но они также требуют выделенной инфраструктуры центра обработки данных, потребляют значительно больше 8 кВт и имеют сроки поставки, которые могут превышать год. Grando жертвует частью этих возможностей расширения периферийных устройств ради системы, которая работает достаточно тихо, чтобы находиться в одном помещении с пользователями, выделяет меньше тепла в окружающую среду и доступна для заказа уже сейчас. Для организаций, которые отдают приоритет быстрому развертыванию и управляемым операционным средам, а не максимальной связности сети, этот компромисс является выгодным.
Заказать такой можно через sales@server-pro.by или страницу контакты.
https://www.storagereview.com/


