
Специалисты компании storagereview произвели тестирование и обзор с помощью программы JumpStart от Supermicro, которая служит средством предварительной оценки инфраструктуры для ИИ. Вместо заранее подготовленной демонстрации в общей среде, JumpStart предоставляет квалифицированным пользователям бесплатный, ограниченный по времени, доступ к реальным производственным серверам через SSH, IPMI и VNC, позволяя им запускать рабочие нагрузки на реальном оборудовании. В ноябре прошлого года специалисты компании storagereview подробно рассмотрели эту программу, используя систему X14 с NVIDIA HGX B200 , и получили представление о том, что может и чего не может дать неделя целенаправленного доступа. На этот раз Supermicro предоставила доступ к системе H14 8U с совершенно иным ускорителем.
Протестировали систему AS-8126GS-TNMR с воздушным охлаждением 8U, на базе 2х AMD EPYC 9575F и 8х AMD Instinct MI350X. MI350X — это флагманский на 2026 год от AMD имеющий 288 ГБ памяти HBM3e на каждый графический процессор. Восемь GPU соединенных через AMD Infinity Fabric, обеспечивают в общей сложности 2,3 ТБ памяти для графических процессоров на одном узле, с общей пропускной способностью 1024 ГБ/с. Вся система использует шесть блоков питания Titanium мощностью 5.25 кВт в конфигурации 3+3 с резервированием, а Supermicro выделила выделенную сеть 400 Гбит/с на каждый графический процессор для масштабируемых развертываний.

В конце 2025 года в проект vLLM был добавлен выделенный конвейер AMD ROCm CI, что сделало оборудование AMD первоклассной платформой в этом стеке инференции, а не просто портом из нисходящего потока. Внедрение экосистемы также трудно игнорировать: в феврале 2026 года AMD и Meta объявили о многолетнем соглашении о развертывании 6-гигаваттных GPU-систем разных поколений, основанном на существующих производственных развертываниях Meta на оборудовании серий MI300 и MI350.
Для организаций, которые в настоящее время оценивают инфраструктуру для ускорения ИИ, сроки поставки оборудования NVIDIA остаются проблемой, так как присутствуют большие очереди на ускорители. Вопрос в том, является ли AMD достойной альтернативой, а не запасным вариантом. На основе недельного тестирования с ROCm 7.2.0 и текущей версией vLLM ответ существенно отличается от того, что было 18 месяцев назад.

В ходе тестирования произведен охват ряд популярных моделей; 2,3 ТБ памяти HBM3e на одном узле позволили выполнять вычисления на одном сервере для моделей с большим количеством параметров, включая Kimi K2.5 и MiniMax M2.5 от Moonshot.
GPU AMD Intinct MI350X: архитектура в стравнении с предыдущим поколений
Основное отличие от серии MI300 к серии MI350 заключается в использовании технологического процесса TSMC N3P для вычислительных чиплетов ускорителей (XCD), в отличие от 5-нм технологии, применявшейся в предыдущем поколении. Общее количество транзисторов достигает приблизительно 185 миллиардов, что примерно на 21% больше, чем в поколении MI300, при этом энергопотребление не увеличивается.
MI350X сохраняет проверенную стратегию AMD по многочиповой компоновке. В основе графического процессора лежат восемь вычислительных чиплетов-ускорителей (XCD), являющихся основными вычислительными ядрами. Каждый XCD содержит четыре шейдерных ядра, каждое с восемью активными вычислительными блоками CDNA 4, что в сумме составляет 32 вычислительных блока на XCD и 256 вычислительных блоков для всего ускорителя.
В конструкции корпуса CDNA 4 слой ввода-вывода также был унифицирован с четырех блоков до двух. Эта реорганизация позволила AMD удвоить ширину шины Infinity Fabric, улучшив пропускную способность в двухсекционном режиме, одновременно снизив частоту шины и рабочее напряжение для уменьшения энергопотребления.
Модернизированные вычислительные блоки и расширенная поддержка высокоточных вычислений.
Благодаря продвинутым возможностям матричной математики вычислительных блоков CDNA 4 достигается существенное повышение производительности: вычислительные блоки MI350 обеспечивают двукратное увеличение пропускной способности на один блок для 16-битных (BF16, FP16) и 8-битных (FP8, INT8) операций по сравнению с их аналогами MI300.
Так же CDNA 4 обеспечивает аппаратную поддержку типов данных с более низкой точностью, отсутствующих в серии MI300, а именно FP6 и FP4, наряду с существующей поддержкой FP8, унаследованной от предыдущего поколения.
В дополнение к этим стандартным форматам, MI350X добавляет встроенную аппаратную поддержку вариантов микромасштабирования OCP: MXFP4, MXFP6 и MXFP8. Форматы микромасштабирования разработаны для обеспечения преимуществ в пропускной способности вычислений с более низкой точностью при сохранении качества выходных данных, более близкого к базовым показателям с более высокой точностью, чем это обычно позволяет стандартное квантование. Это не разработка, специфичная для AMD. Формат NVFP4 от NVIDIA работает на тех же принципах микромасштабирования и получил широкое распространение в передовых системах обработки моделей, причем семейство GPT-OSS от OpenAI является одним из наиболее ярких примеров, построенных на основе этих форматов. Встроенная поддержка MXFP4 в MI350X позволяет ему работать с этими и аналогичными семействами квантованных моделей без необходимости использования программной эмуляции или повышения точности.
MI350X обеспечивает 9,2 PFLOPs при MXFP4 и MXFP6, по сравнению с 4,6 PFLOPs при OCP-FP8, при этом FP16 составляет 2,3 PFLOPs, а пиковая тактовая частота ядра — 2200 МГц. Для оптимизированных для вывода развертываний, где возможно микромасштабное квантование, вычислительный потенциал фактически удваивается по сравнению с рабочими нагрузками FP8. В вычислительный блок CDNA 4 также добавлен новый векторный АЛУ, поддерживающий 2-битные операции и способный накапливать результаты BF16 в FP32, что обеспечивает дополнительную гибкость для векторных рабочих нагрузок с низкой точностью вне основного пути матричных вычислений.
Подсистема памяти: HBM3e, бесконечный кэш и эффективность использования полосы пропускания.
Серия GPU AMD MI350 значительно отличается улучшенной подсистемой памяти с восемью стеками памяти HBM3e, обеспечивающими общую емкость 288 ГБ на каждый графический процессор. Каждый стек объемом 36 ГБ, состоящий из 12 устройств высотой 24 Гбит/с, работает на полной скорости вывода HBM3e — 8 Гбит/с на вывод. Архитектура сохраняет кэш-память AMD Infinity Cache, расположенную между HBM и кэшами Infinity Fabric/L2. Она включает 128 каналов, каждый из которых поддерживается 2 МБ кэша, что в сумме составляет 256 МБ на каждый графический процессор. AMD расширила встроенные сетевые шины внутри IOD и работает при пониженном напряжении, что обеспечивает примерно в 1,3 раза большую пропускную способность памяти на ватт по сравнению с серией MI300.
Увеличение объема памяти с 192 ГБ у MI300X до 288 ГБ расширяет лидерство AMD по запасу памяти на каждый графический процессор, что имеет прямое значение для вывода больших моделей. Каждый графический процессор MI350X может независимо обрабатывать модели с более чем 500 миллиардами параметров. В восьмипроцессорном сервере совокупный объем памяти HBM3e в 2,3 ТБ устраняет необходимость в многоузловом распределении, которое усложняет развертывание систем с триллионами параметров, как показывают результаты Kimi K2.5 и MiniMax M2.5 в этом обзоре.
Гибкая архитектура разделения и развертывания
Серия MI350 поддерживает гибкое разделение памяти на графические процессоры для каждого сокета, при этом память разделяется на два отдельных кластера. Эта гибкость также распространяется на XCD, где кластер из четырех XCD может быть разделен на два или один блок, что позволяет чипу поддерживать такие конфигурации, как 8 экземпляров 70-битных моделей в CPX+NPS2. Для организаций, использующих гетерогенные рабочие нагрузки вывода в общей инфраструктуре, эта возможность разделения памяти снижает потребность в выделенном оборудовании для каждого уровня моделей и повышает экономическую эффективность использования в средах смешанного развертывания.
Серия MI350 также сохраняет совместимость с инфраструктурой UBB (Universal Base Board), используемой в системах серии MI300. Существующие серверные шасси, система питания и охлаждения сохраняются без изменений, что снижает сложности при модернизации для организаций, уже использующих системы MI300.
MI355X: версия с жидкостным охлаждением
Серия MI350 выпускается в двух вариантах, построенных на идентичной базовой кремниевой основе и оптимизированных для различных температурных режимов работы. Протестированная модель MI350X имеет воздушное охлаждение, а MI355X — жидкостное охлаждение, предназначенное для развертывания в условиях высокой плотности размещения оборудования, где доступна инфраструктура прямого жидкостного охлаждения.
Хотя оба варианта построены на одном и том же базовом оборудовании, более высокое энергопотребление MI355X позволяет поддерживать более высокие тактовые частоты, что обеспечивает приблизительно 20% преимущество в производительности в реальных сквозных нагрузках по сравнению с MI350X. Максимальное энергопотребление MI355X составляет 1400 Вт против 1000 Вт у MI350X, а тактовая частота достигает 2,4 ГГц по сравнению с 2,2 ГГц у варианта с воздушным охлаждением.
В сравнении с предыдущим поколением, платформа MI355X обеспечивает до 4-кратного повышения пиковой теоретической производительности по сравнению с MI300X, с реальным приростом производительности примерно в 4,2 раза в задачах с агентами и чат-ботами и примерно в 3 раза в сценариях генерации контента. Для организаций, оценивающих возможность развертывания MI350X, 20-процентная разница в производительности между двумя вариантами представляет собой явный потолок. Предприятиям с инфраструктурой DLC следует оценить MI355X, чтобы определить, обеспечит ли теплоотвод достаточное увеличение пропускной способности для их конкретного профиля рабочей нагрузки, прежде чем принимать решение о масштабируемом использовании конфигураций с воздушным охлаждением.
Доступ к AMD Intinct MI350X через программу Supermicro JumpStart
Для начала работы с JumpStart необходимо зарегистрироваться на портале Supermicro, где квалифицированные пользователи могут просмотреть доступные системы и запланировать период бронирования. Однако в связи с известными событиями компании в Республике Беларусь и Российской Федерации - этого сделать не могут, по-этому можно довольствоваться только статьями или платно получить доступ к тестированию похожих платформ у компании Selectel, однако маловероятно что GPU на MI350X будут доступны для тестирования, а если будут достпуны - это конечно же будет платно. После одобрения портал предоставляет учетные данные SSH, доступ к IPMI и веб-консоль для удаленного доступа на весь период бронирования. Система поставляется с предустановленной Ubuntu и готова к использованию. Нет задержки в настройке и не требуется обращение в службу поддержки для начала работы. Бронирование компании toragereview длилось с 23 по 27 марта 2026 года, что дало целую неделю работы на платформе, как и в случае с предыдущим участием в программе JumpStart на HGX B200.
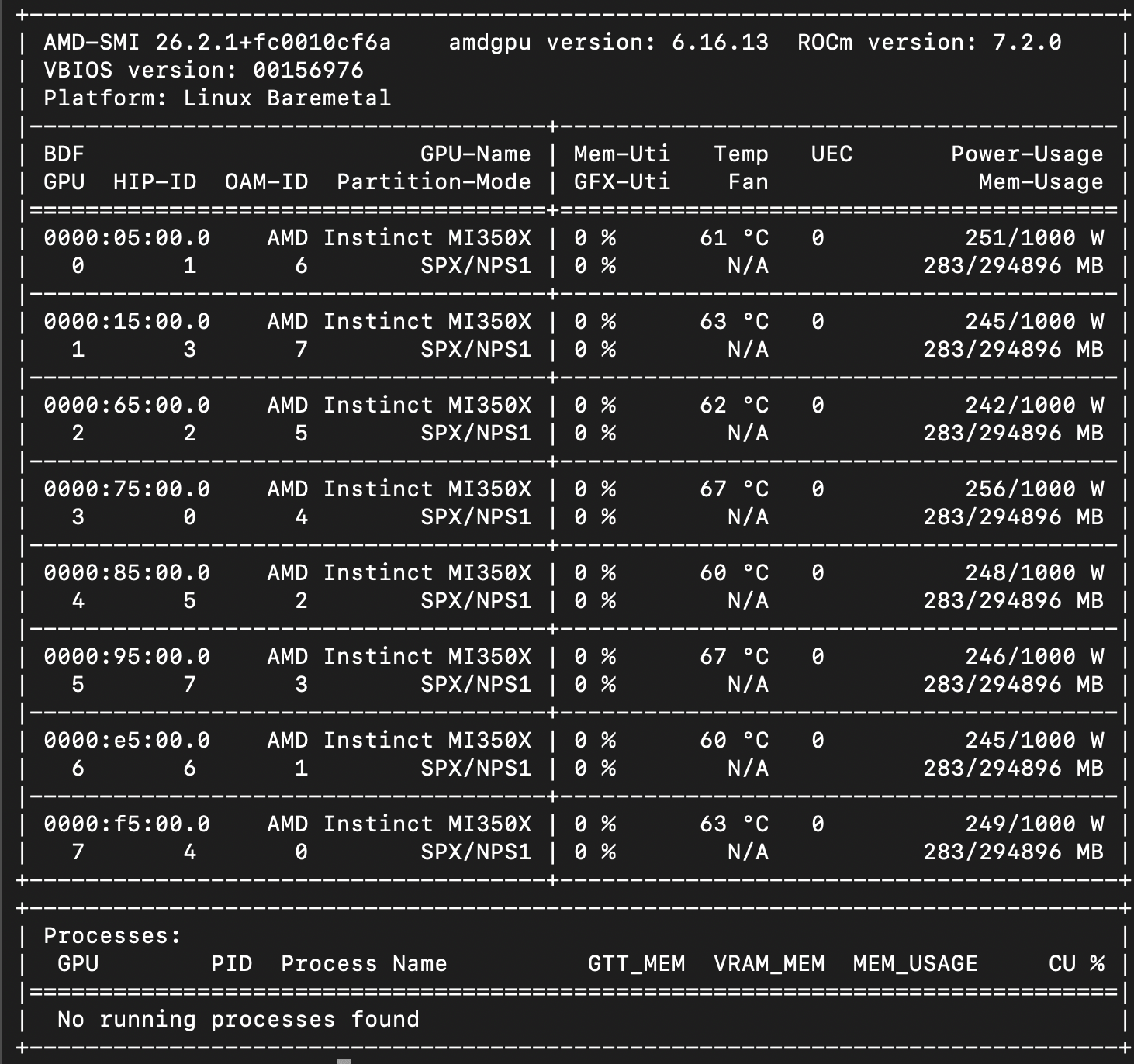
На скриншоте ниже показан вывод терминала после запуска системы H14 с помощью инструмента AMD-SMI, отображающего восемь графических процессоров AMD Instinct MI350X и версии их программного обеспечения.
Результаты тестирования производительности AMD Instinct MI350X
Конфигурация системы
- Корпус: Supermicro H14
- Процессор: Два AMD EPYC 9575F
- Память: 3 ТБ DDR5
- Видеокарты: восемь AMD Instinct MI350X
- Хранение данных: 2 твердотельных накопителя PCIe 4.0 M.2 NVMe по 3,8 ТБ и 1 твердотельный накопитель NVMe M.2 по 1,92 ТБ.
Краткое изложение результатов
| Модель | Точность | Равно (256/256) | Предварительно заполняемый (8k/1k) | Интенсивное декодирование (1k/8k) |
|---|---|---|---|---|
| GPT-OSS 20B | NVFP4 | 62,247 | 123,714 | 32,468 |
| GPT-OSS 120B | NVFP4 | 33,538 | 84,018 | 20 602 |
| Лама 3.1 8B Инструкция | БФ16 | 51,467 | 77,658* | 19,326 |
| Mistral Small 3.1 24B | FP8 | 40,742 | 56,093 | 14,557 |
| Mistral Small 3.1 24B | БФ16 | 30,530 | 53,740 | 13,559 |
| Qwen3 Coder 30B A3B | БФ16 | 34,980 | 51,550 | 11,782 |
| Qwen3 Coder 30B A3B | FP8 | 25,928 | 47,179 | 11,014 |
| Минимакс М2.5 | Блочно-масштабируемый FP8 | 14,391 | 23,689 | 6068 |
| Kimi K2.5 | INT4 QAT + BF16 | 6,527 | 11,256 | 2513 |
| Все значения указаны в токах/с, пиковая пропускная способность при BS=256. *Llama 3.1 8B prefill-heavy достигла пика при BS=128 (77 658 токов/с); при BS=256 — 76 893 токов/с. | ||||
Claude Code Serving – MiniMax M2.5
Помимо традиционных тестов производительности LLM-вычислений, возникает интерес, насколько хорошо все работает в процессе агентного программирования, обслуживая несколько одновременных сессий Claude Code с локально размещенной моделью. Этот сценарий связан с производительностью команды разработчиков: сколько инженеров, вайб коддеров или обычных сотрудников могут одновременно использовать помощника по программированию на основе ИИ, работающего с одного узла, прежде чем качество работы ухудшится?
Для проверки этого создана тестовая среда, которая генерирует набор данных из задач программирования средней сложности (задачи, такие как реализация LRU-кэша, создание приложения для управления задачами в командной строке, написание конвертера Markdown и разработка REST API) и запускает каждую сессию Claude Code в отдельном контейнере Docker с использованием локального сервера vLLM. Между сессиями и конечной точкой вывода находится прозрачный прокси-сервер, который собирает метрики для каждого запроса для каждого экземпляра Claude Code. Использовалась модель MiniMax M2.5, работающая через vLLM на восьми графических процессорах MI350X. Хотя M2.5 не является лучшей моделью программирования в публичных рейтингах, это мощная модель, которую многие пользователи запускают локально, включая многих наших друзей-разработчиков.
В качестве базового показателя используем среднюю пропускную способность Anthropic Claude Opus 4.6, полученную через OpenRouter.ai, один из самых популярных сервисов маршрутизации для доступа к API в производственной среде. Этот базовый показатель составляет приблизительно 37 токенов в секунду на один запрос к API.
Измерили два ключевых показателя: среднее количество выходных токенов в секунду за сессию Claude Code (то, что обрабатывает каждый разработчик) и совокупное количество выходных токенов в секунду по всем сессиям (общий объем работы, выполняемой сервером) полученные результаты ниже.
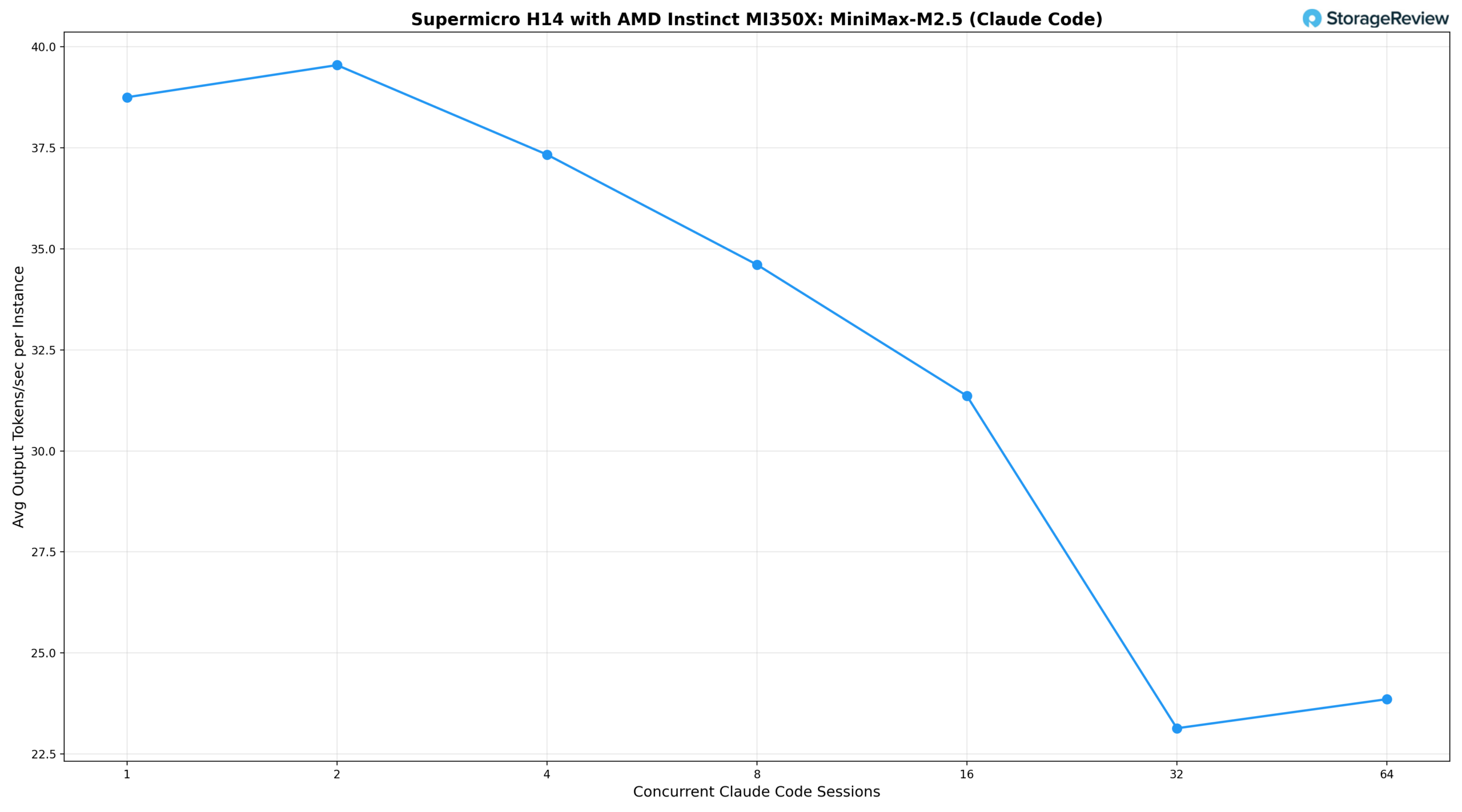
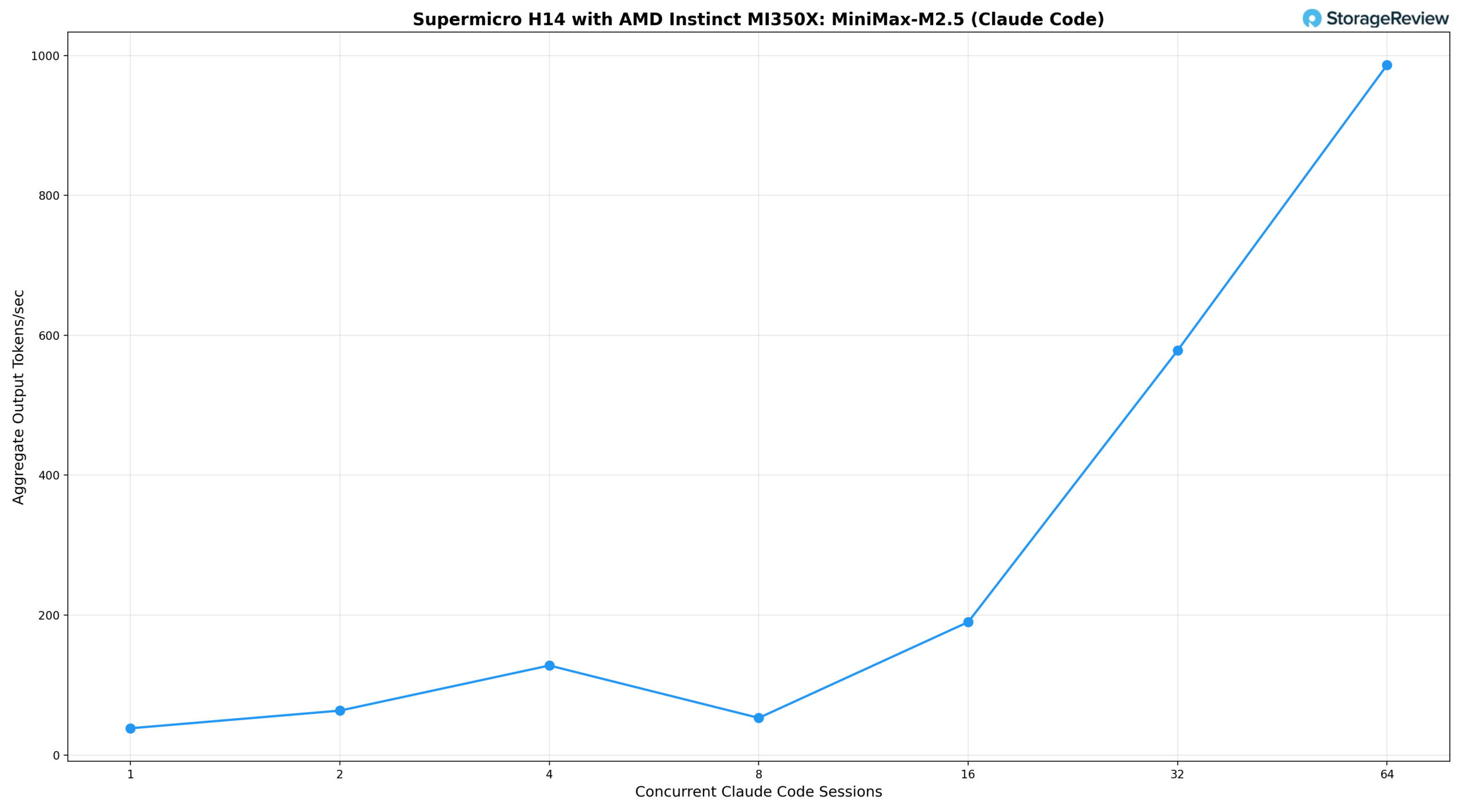
Анализируя результаты, видно, что одна одновременная сессия обеспечивает 38,8 ток/с на пользователя и 38 ток/с в сумме, что немного выше базового показателя облачной платформы OpenRouter. При двух сессиях система немного увеличивает пропускную способность до 39,5 ток/с на пользователя, поскольку пакетная обработка vLLM начинает амортизировать накладные расходы, а общая пропускная способность возрастает до 63 ток/с. Четыре одновременные сессии обеспечивают 37,3 ток/с на пользователя, что соответствует базовому показателю облачной платформы при одновременном обслуживании четырех разработчиков, а общая пропускная способность достигает 128 ток/с. Начиная с восьми сессий, пропускная способность на экземпляр начинает снижаться: 34,6 ток/с на пользователя при восьми сессиях, 31,4 ток/с при шестнадцати с суммарной пропускной способностью 190 ток/с, и стабилизируется на уровне около 23 ток/с на пользователя при 32 и 64 сессиях, в то время как общая пропускная способность возрастает до 578 ток/с и 986 ток/с соответственно. Это классический компромисс между пропускной способностью пакетной обработки и интерактивностью: система может достичь значительно большей общей пропускной способности за счет пакетной обработки большего количества запросов, но каждый пользователь будет испытывать замедление времени отклика. Даже при 64 одновременно работающих пользователях каждый разработчик по-прежнему получает приемлемый интерактивный опыт, хотя и заметно медленнее, чем в облачной среде.
Для организаций, взвешивающих стоимость десятков одновременных коммерческих подписок на API по сравнению с собственной инфраструктурой, компромисс очевиден: один узел MI350X может обслуживать команду разработчиков из 16–32 инженеров, поддерживая скорость ответа на пользователя в пределах 60–85% от базового уровня облака и обеспечивая совокупную производительность от 600 до 1000 токенов в секунду, с дополнительными преимуществами локализации данных, отсутствием платы за API за токен и полным контролем над выбором модели.
Онлайн-сервис vLLM – Производительность вывода данных LLM
Онлайн-бенчмарк vLLM оценивает реальную производительность механизма вывода при одновременных запросах. Он имитирует производственные нагрузки, отправляя запросы на работающий сервер vLLM с настраиваемыми параметрами, такими как скорость запросов, длина входных/выходных данных и количество одновременно работающих клиентов. Бенчмарк измеряет ключевые показатели, включая пропускную способность (токены в секунду), время до получения первого токена и время на один выходной токен (TPOT), помогая пользователям понять, как vLLM работает в различных условиях нагрузки.
GPT-OSS 120B и 20B
Семейство моделей GPT-OSS было протестировано в конфигурациях 120B и 20B на материнской плате Supermicro H14.
GPT-OSS 120B
Модель 120B при одинаковой нагрузке (256/256) обеспечивает производительность 313,42 токн/с при BS=1, достигает 11 261,72 токн/с при BS=64 и пикового значения 33 538,23 токн/с при BS=256. При интенсивном предварительном заполнении (8 тыс./1 тыс.) производительность начинается с 1724,84 токн/с, увеличивается до 36 156,80 токн/с при BS=32 и 79 247,76 тонн/с при BS=128, достигая пикового значения 84 018,79 токн/с при BS=256. Интенсивность декодирования (1k/8k) возрастает с 288,90 ток/с при BS=1 до 20 602,52 ток/с при BS=256, при этом задержка остается хорошо контролируемой при более низких уровнях параллелизма.
GPT-OSS 20B
Модель 20B обеспечивает производительность 485,17 токн/с при BS=1 при одинаковой нагрузке, достигая 17 986,36 токн/с при BS=64 и пикового значения 62 247,52 токн/с при BS=256. При интенсивном предварительном заполнении производительность начинается с 3 120,72 токн/с, увеличивается до 48 132,52 токн/с при BS=32 и 83 968,71 токн/с при BS=64, достигая пикового значения 123 714,50 токн/с при BS=256 — это самая высокая абсолютная производительность предварительного заполнения, зарегистрированная для обеих моделей. Скорость декодирования увеличивается с 378,20 ток/с при BS=1 до 32 468,67 ток/с при BS=256, обеспечивая примерно в 1,6 раза большую пропускную способность декодирования по сравнению с 120B при пиковой параллельности, сохраняя при этом более жесткие характеристики задержки.
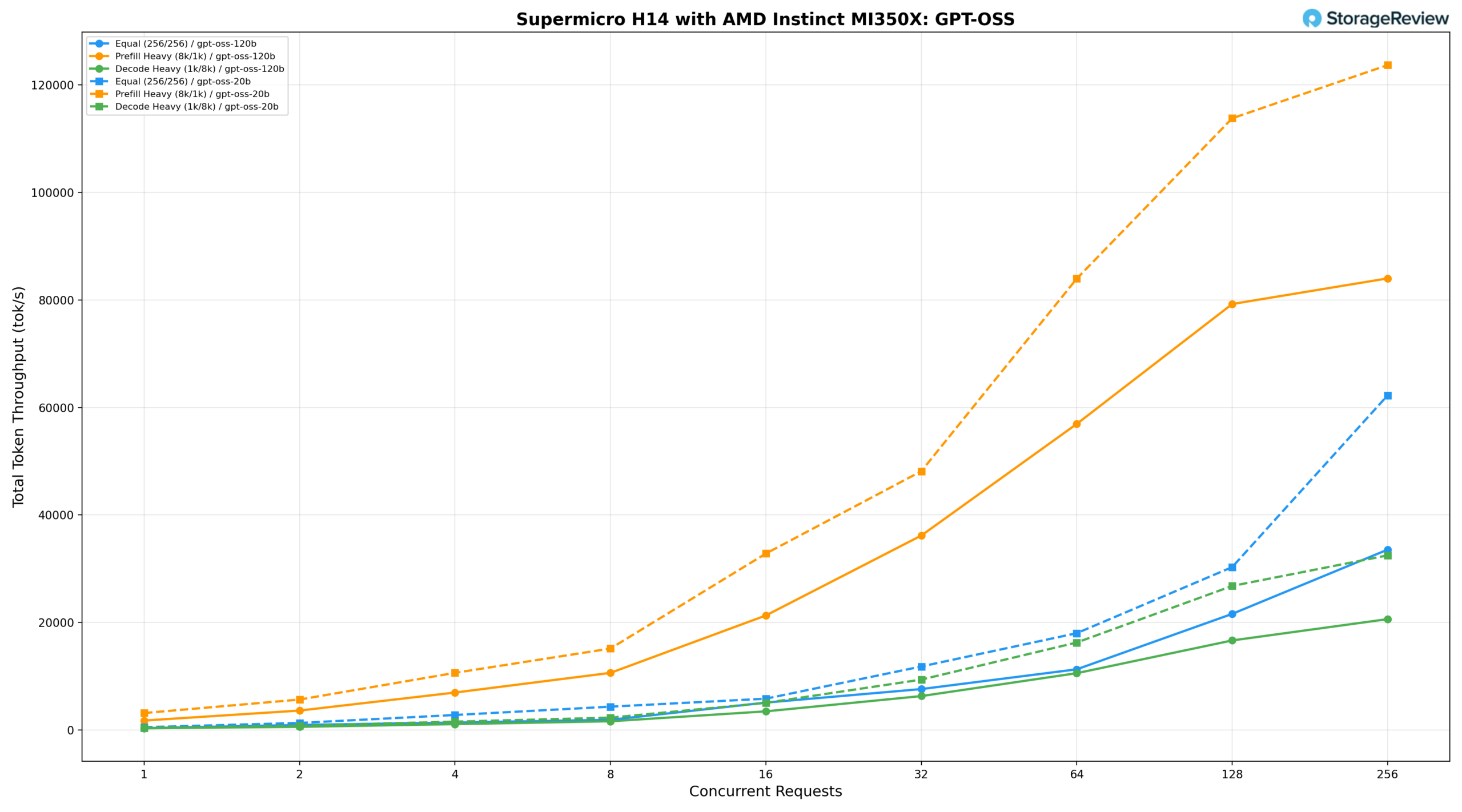
Qwen3 Coder 30B A3B Instruct и FP8 Instruct
Инструкция Qwen3-Coder-30B-A3B-Instruct на плате Supermicro H14 была протестирована как в стандартном (BF16), так и в режиме FP8.
Qwen3-Coder-30B-A3B-Instruct (BF16)
На BF16 при равной нагрузке (256/256) производительность составляет 240,53 ток/с при BS=1, достигая 13 312,70 ток/с при BS=64 и 21 333,79 ток/с при BS=128, с пиковой производительностью 34 980,97 ток/с при BS=256. При предварительной загрузке (8 тыс./1 тыс.) производительность начинается с 1276,76 ток/с, увеличивается до 25 069,32 ток/с при BS=32 и 50 198,94 ток/с при BS=128, достигая пика в 51 550,66 ток/с при BS=256. Скорость декодирования (1k/8k) неуклонно возрастает примерно со 188 ток/с при BS=1 до 11 782 ток/с при BS=256, сохраняя самый низкий уровень задержки среди трех сценариев.
Qwen3-Coder-30B-A3B-Instruct (FP8)
Вариант FP8 обеспечивает скорость 188,92 ток/с при BS=1 при одинаковой нагрузке, достигая 10 866,27 ток/с при BS=64 и 17 617,60 ток/с при BS=128, с пиковым значением 25 928,77 ток/с при BS=256 — немного отставая от результатов BF16 во всем диапазоне. При интенсивном предварительном заполнении скорость начинается с 860,07 ток/с, увеличивается до 20 513,77 ток/с при BS=32 и 44 205,46 ток/с при BS=128, достигая пикового значения 47 179,15 ток/с при BS=256. Интенсивность декодирования возрастает со 133,79 ток/с при BS=1 до 11 014,95 ток/с при BS=256, стабильно увеличиваясь и оставаясь близкой к BF16 на протяжении всего процесса.
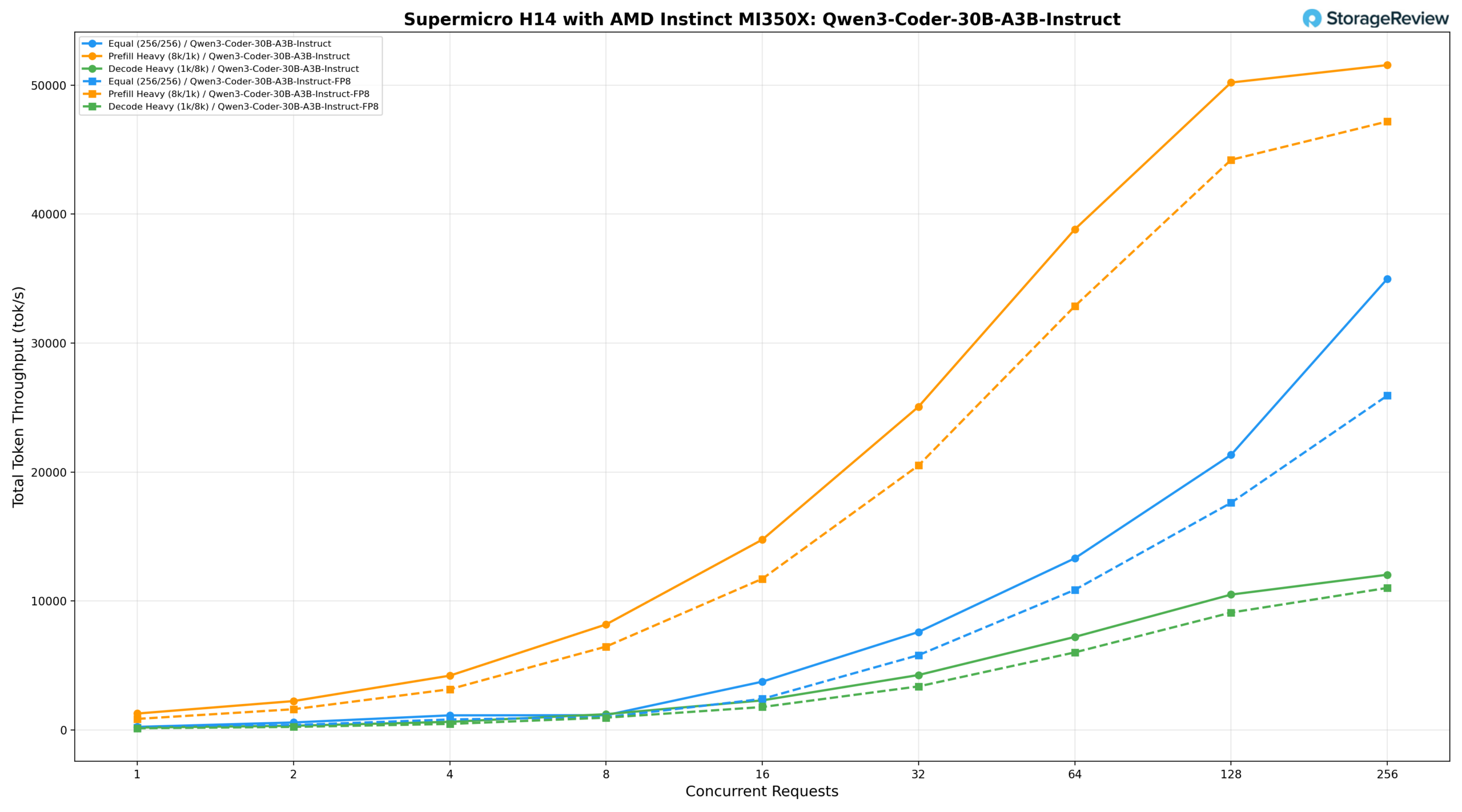
Mistral Small 3.1 24B Инструкция 2503
Модуль Mistral-Small-3.1-24B-Instruct-2503 на плате H14 был протестирован как в стандартном режиме, так и в режиме FP8-динамической точности, показав стабильное масштабирование во всех трех профилях рабочей нагрузки.
Mistral-Small-3.1-24B-Instruct-2503 (BF16)
При точности BF16, равная загрузка (256/256) обеспечивает скорость 236,15 ток/с при BS=1, достигая 15 494,56 ток/с при BS=64, 24 216,52 ток/с при BS=128 и пикового значения 30 530,54 ток/с при BS=256. При предварительной загрузке (8k/1k) скорость начинается с 1429,41 ток/с, увеличивается до 29 631,68 ток/с при BS=32 и 54 871,74 ток/с при BS=128, достигая пикового значения 53 740,04 ток/с при BS=256. Скорость декодирования (1k/8k) возрастает с 242,66 ток/с при BS=1 до 13 559,19 ток/с при BS=256, стабильно увеличиваясь во всем диапазоне.
Mistral-Small-3.1-24B-Instruct-2503 (FP8-dynamic)
FP8-dynamic FP8 обеспечивает скорость 184,25 ток/с при BS=1 при одинаковой нагрузке, достигая 16 113,95 ток/с при BS=64 и 26 409,01 ток/с при BS=128, с пиковым значением 40 742,04 ток/с при BS=256. При интенсивном предварительном заполнении скорость начинается с 1210,06 ток/с, увеличивается до 28 773,52 ток/с при BS=32 и 57 765,02 ток/с при BS=128, достигая пикового значения 56 093,09 ток/с при BS=256, опережая стандартный результат точности, начиная с BS=64. Интенсивность декодирования возрастает со 183,94 ток/с при BS=1 до 14 557,94 ток/с при BS=256, оставаясь близкой к среднему диапазону, прежде чем немного вырваться вперед при BS=128 и BS=256.
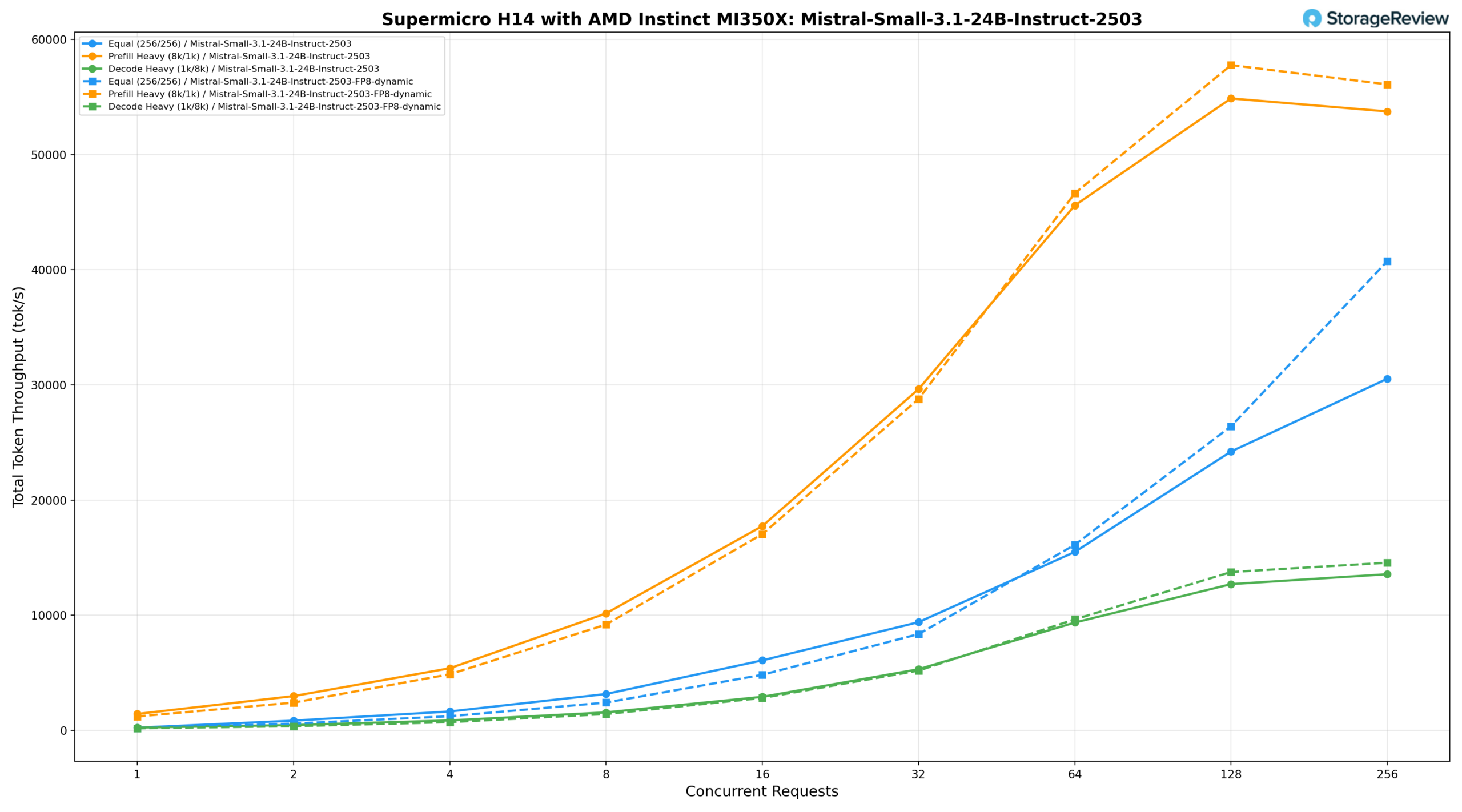
LIama 3.1 8B Инструкция
Для инструкции Llama-3.1-8B мы наблюдали, что при одинаковой нагрузке (256/256) скорость составляет 373,26 ток/с при BS=1, достигая 19 363,33 ток/с при BS=64, 34 155,70 ток/с при BS=128 и пикового значения 51 467,30 ток/с при BS=256. При интенсивном предварительном заполнении (8k/1k) скорость начинается с 1959,04 ток/с, увеличивается до 37 227,63 ток/с при BS=32 и 60 062,40 ток/с при BS=64, достигая пикового значения 77 658,50 ток/с при BS=128, а затем немного снижается до 76 893,77 ток/с при BS=256. В режиме интенсивного декодирования (1k/8k) скорость начинается с 326,48 ток/с, достигая 17 877,52 ток/с при BS=128 и 19 326,35 ток/с при BS=256, поддерживая более низкую задержку на токен даже в диапазоне параллельного выполнения, чем любая из протестированных более крупных моделей.
MINIMAX М2.5
Модель MiniMax-M2.5 на H14 завершает модельный ряд, занимая промежуточное положение между Kimi K2.5 и моделями среднего размера по профилю производительности, с характеристиками, отражающими его архитектуру, сочетающую в себе функции нескольких специалистов. При одинаковой нагрузке (256/256) производительность составляет 79,31 ток/с при BS=1, достигая 5029,76 ток/с при BS=64, 7801,10 ток/с при BS=128 и 14391,98 ток/с при BS=256. В сценарии с интенсивным предварительным заполнением (8k/1k) наблюдается наиболее сильное увеличение скорости из трех, начиная с 424,41 ток/с и достигая 10 376,75 ток/с при BS=32 и 20 658,57 ток/с при BS=128, с пиком в 23 689,18 ток/с при BS=256. В сценарии с интенсивным декодированием (1k/8k) скорость стабильно увеличивается до 4 257,68 ток/с при BS=128 и 6 068,70 ток/с при BS=256, демонстрируя наиболее стабильный рост задержки во всем диапазоне параллелизма.
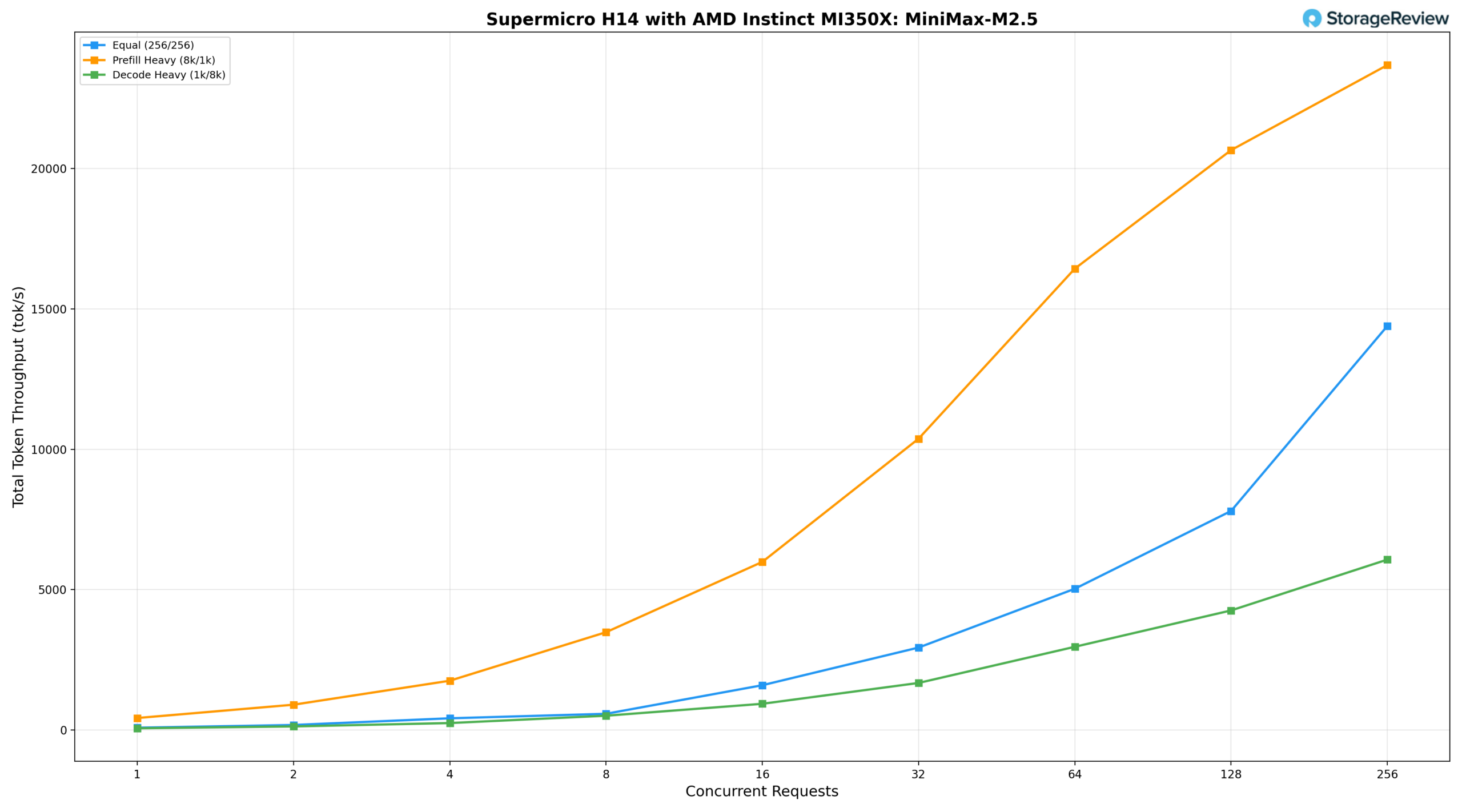
Kimi K2.5
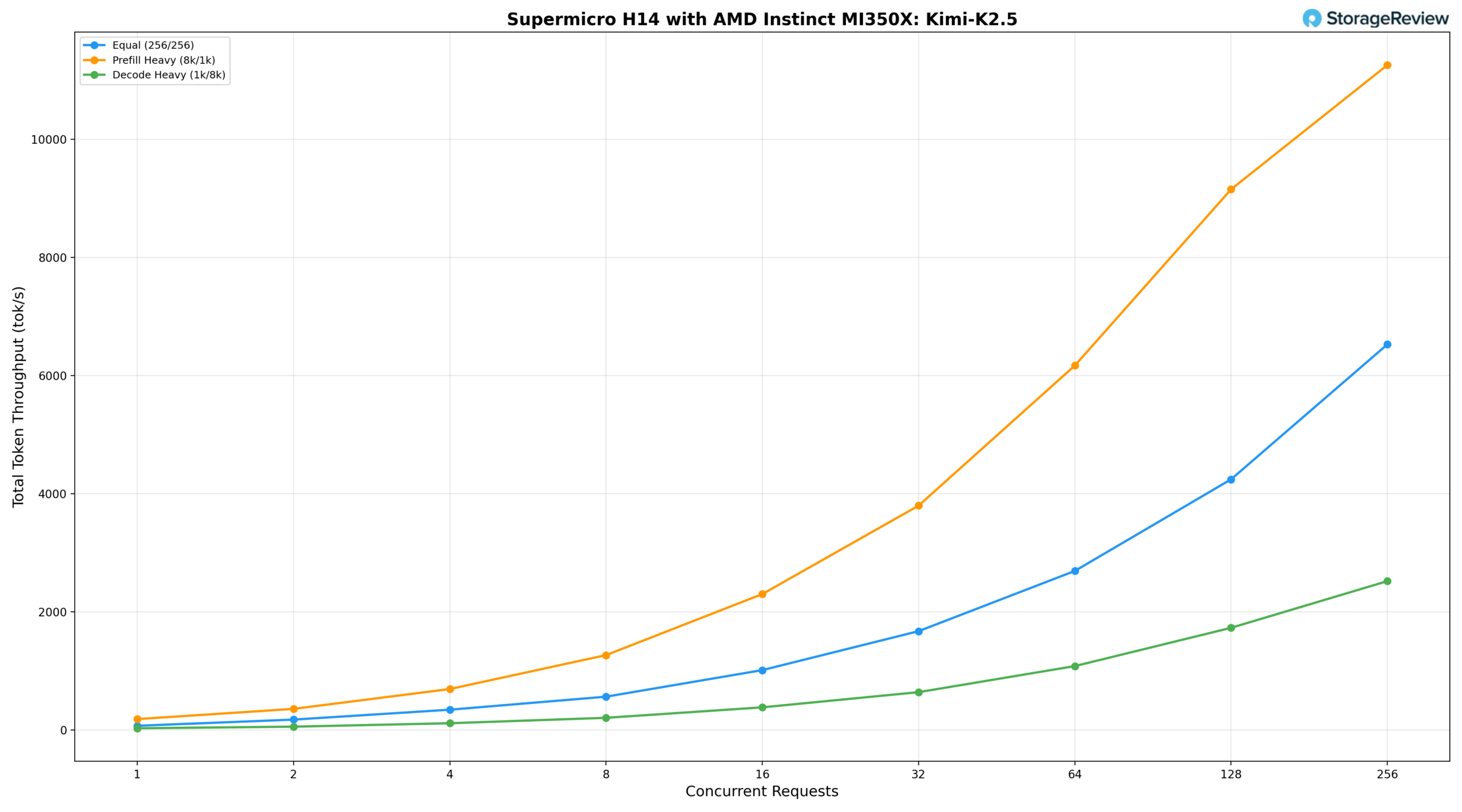
Модель Kimi K2.5 с 1 триллионом параметров на H14 является самой крупной и интеллектуальной моделью из протестированных в этом обзоре, и ее пропускная способность отражает этот вес.
Равномерная нагрузка (256/256) обеспечивает производительность 72,06 ток/с при BS=1, достигая 2693,07 ток/с при BS=64, 4244,27 ток/с при BS=128 и пикового значения 6527,62 ток/с при BS=256. При высокой нагрузке с предварительным заполнением (8k/1k) производительность масштабируется более агрессивно, начиная с 185,29 ток/с и достигая 3798,85 ток/с при BS=32 и 9153,12 ток/с при BS=128, с пиковой пропускной способностью 11256,69 ток/с при BS=256. Скачкообразное увеличение от BS=128 до BS=256 влечет за собой значительные задержки, что указывает на приближение системы к пределам памяти и вычислительных мощностей при полной глубине пакета для данного размера модели. В сценариях с интенсивным декодированием (1k/8k) скорость увеличивается с 29,88 ток/с при BS=1 до 2513,85 ток/с при BS=256, обеспечивая наиболее точную кривую масштабирования из трех сценариев и демонстрируя стабильное увеличение пропускной способности во всем диапазоне.
Выводы
AMD Instinct MI350X демонстрирует конкурентоспособную производительность при выполнении задач инференции в рамках протестированных профилей рабочих нагрузок. Благодаря 288 ГБ памяти HBM3e на каждый ускоритель и восьми графическим процессорам, объединенным по протоколу Infinity Fabric, 2,3 ТБ совокупной памяти GPU, доступной в одном узле, достаточно для обслуживания моделей с триллионами параметров, таких как Kimi K2.5 и MiniMax M2.5, без необходимости многоузлового распределения или обходных путей разделения моделей. Эта возможность существенно упрощает архитектуру развертывания для крупномасштабной инференции.
В целом, результаты указывают на аппаратную платформу, которая предсказуемо масштабируется под нагрузкой, а не резко падает при большей глубине пакетной обработки.

ROCm 7.2 вносит значительные улучшения в программный стек AMD для выполнения инференции, особенно в сочетании с vLLM 0.18. Это сочетание обеспечивает заметно более стабильную и высокопроизводительную работу сервиса по сравнению с предыдущими поколениями ROCm, с более широкой поддержкой фреймворков и меньшим количеством шероховатостей, характерных для более ранних развертываний Instinct. Также стоит отметить развитие экосистемы вокруг оборудования AMD: vLLM теперь поддерживает выделенный конвейер CI для AMD ROCm, а обязательство Meta по развертыванию в нескольких поколениях в масштабе 6 гигаватт подтверждает, что проверка в производственной среде выходит далеко за рамки контролируемых сред бенчмаркинга.
Оценка производительности Claude Code Serving добавляет практический аспект к исходным показателям пропускной способности. Один узел MI350X поддерживал скорость отклика, близкую к базовой для облачных сред, при одновременной обработке до 16 сессий кодирования и оставался интерактивным с 64 пользователями, обеспечивая при этом совокупный объем выходных данных почти в 1000 токенов в секунду. Для организаций, сравнивающих стоимость коммерческих подписок на API с собственной инфраструктурой, экономическая целесообразность становится очевидной при такой плотности, с дополнительными преимуществами в локализации данных, исключении затрат на каждый токен и неограниченном выборе модели.
https://www.storagereview.com/


